
[Deep Learning] CNN에서의 이미지 처리(Image Processing)
이미지 처리 방법의 종류
1) 이미지 분류(Image Classification)
이미지가 어떤 종류인지 확인 하는 것
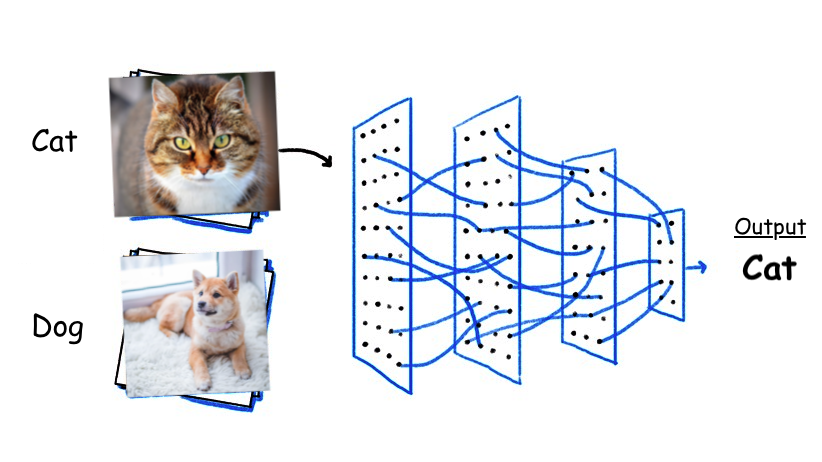
https://towardsdatascience.com/10-papers-you-should-read-to-understand-image-classification-in-the-deep-learning-era-4b9d792f45a7
- 예 : 종양이 있나 없나?
2) 객체 탐지(Object Detection)
이미지에서 어떤 종류의 Object가 어디에 존재하는지 확인하는 것
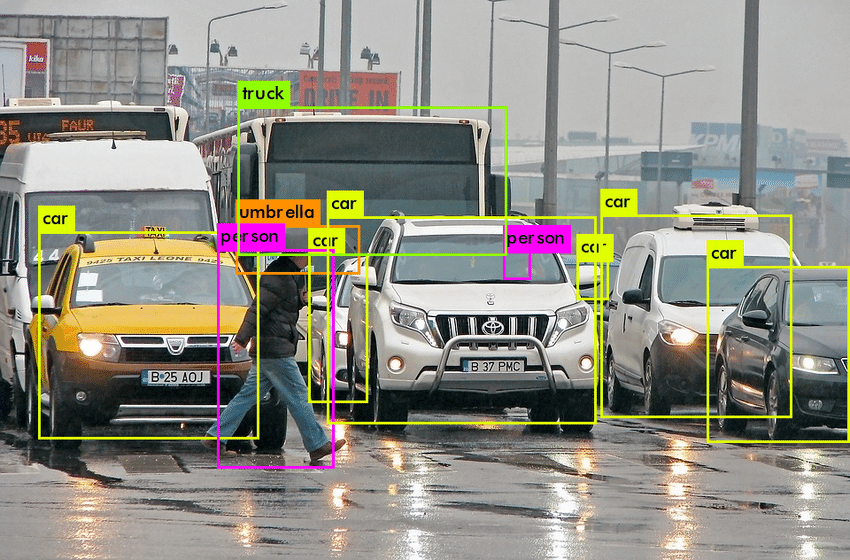
Potdar, Kedar & Pai, Chinmay & Akolkar, Sukrut. (2018). A Convolutional Neural Network based Live Object Recognition System as Blind Aid. 10.13140/RG.2.2.34494.54085.
- 예 : 종양이 어디에 있나?
- 알고리즘 : R-CNN, YOLO
YOLO (You Only Look Once)
이미지를 한번 보는 것만으로 Object의 종류와 위치를 추측하는 객체 탐지 알고리즘
- Bounding box coordination
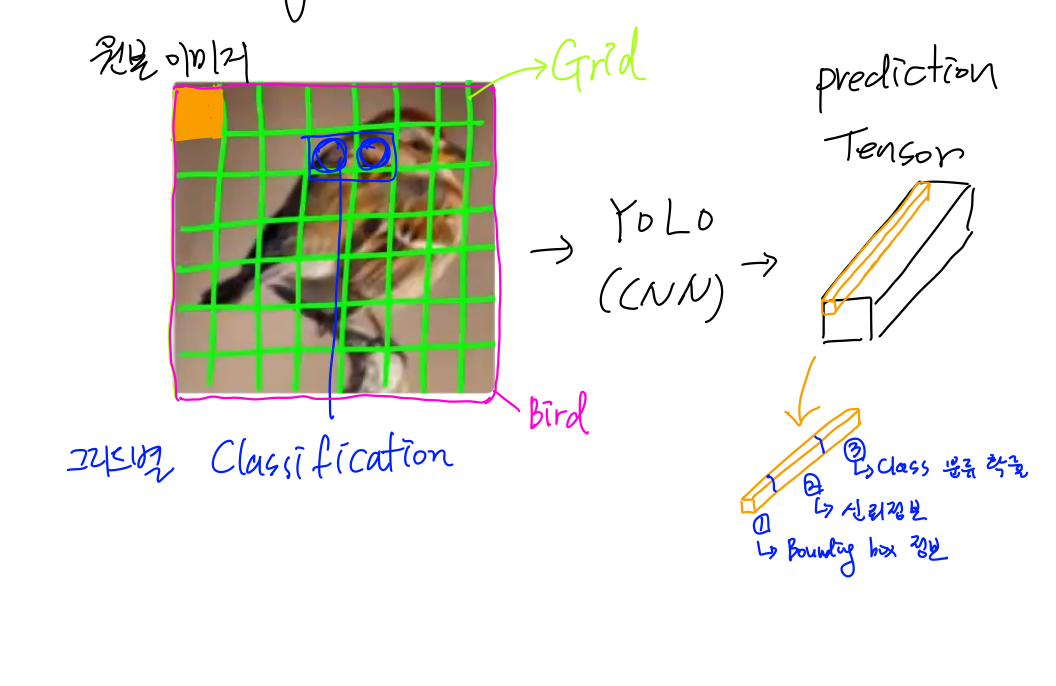
이미지 데이터를 그리드 단위로 쪼개서 그리드별로 분류를 진행한다.
그리드별 분류 결과가 같으면 통합시켜 나가면서 Bounding Box를 넓혀나간다.
원본 이미지가 YOLO를 통과하게 되면 Feature Map이 Tensor 형태로 나온다(Prediction Tensor).
좌측 상단의 ‘주황색’ 그리드는 Prediction Tensor에서 ‘주황색’ 부분에 해당된다.
Prediction Tensor는 3가지 속성을 가지고 있다.
(1) Bounding box 정보 : 새인지, 강아지인지, …
(2) Bounding box 정보에 대한 신뢰 정보 : 0 ~ 1
(3) 객체로 분류했을 때의 확률 : 0 ~ 1
Object Detection Metric은 2가지 이다.
- mAP(mean Average Precision) : 정확도
- FPS(Frame Per Seconds) : 속도
또한, YOLO는 R-CNN 보다 속도는 빠르지만, 상대적으로 정확도가 낮다.
3) 이미지 분할(Image Segmentation)
하나의 이미지를 여러개의 픽셀 집합으로 나누는 것

https://devkor.tistory.com/entry/CS231n-11-Detection-and-Segmentation
- 예 : 종양 위치를 정확하게 확인
- 이미지 분할 학습을 위해서는 Object에 대한 y값(픽셀 단위)이 있어야 학습이 가능하다.
4) 이미지 캡셔닝(Image Captioning)
이미지에 대한 설명을 만들어 내는 것

https://github.com/zzsza/Deep_Learning_starting_with_the_latest_papers/blob/master/Lecture_Note/03.%20CNN%20Application/12.Image-Captioning.md
- 예 : 어느 부위에 종양이 몇 개 있습니다.
Leave a comment