
[Deep Learning] LSTM(Long Short-Term Memory)
1. LSTM(Long Short-Term Memory)
RNN의 장기 의존성 문제를 개선하기 위해 ‘장기 기억’을 사용하는 신경망
RNN은 내부 루프가 존재하는 신경망으로 1개의 Layer에서 반복되는 알고리즘이다.
이전 단계의 정보인 은닉층의 출력(Short-Term Memory)이 계속 순환하면서 입력값과 함께 학습에 사용된다.
RNN은 입력 데이터가 길어질수록, 데이터의 타임스텝이 커질수록 학습 능력이 떨어지고
입력 데이터와 출력 사이의 길이가 멀어질수록(레이어가 많아질수록) 연관 관계가 적어지게 된다.
이러한 문제를 장기 의존성(Long-Term Dependency)이라고 부른다.
예를 들어, 짧은 문장을 번역할 때는 직전 몇개의 단어들만 기억하면 되지만
문장이 길어질 경우 문장 전체의 문맥을 이해할 수 있어야 문장을 완전히 번역할 수 있다.
따라서, 기존 RNN에 Long-Term Memory(Memory Cell) 구조를 추가하여
장기 기억을 가질 수 있는 신경망이 나타나게 된다.
그것이 바로 LSTM이다.
LSTM은 Long-Term Memory(Memory Cell)을 통해
1) Sequence가 깊어지면 기억이 희미해지는 장기 의존성을 해결하고
2) 역전파 과정에서 가중치 학습을 방해하는 경사 소실 및 폭주 문제를 해결할 수 있다.
- 경사 소실(Vanishing Gradient) : 경사값이 점차적으로 작아져 0이되는 현상
- 경사 폭주(Exploding Gradient) : 경사값이 점차적으로 커져 발산하는 현상
2. RNN Vs. LSTM
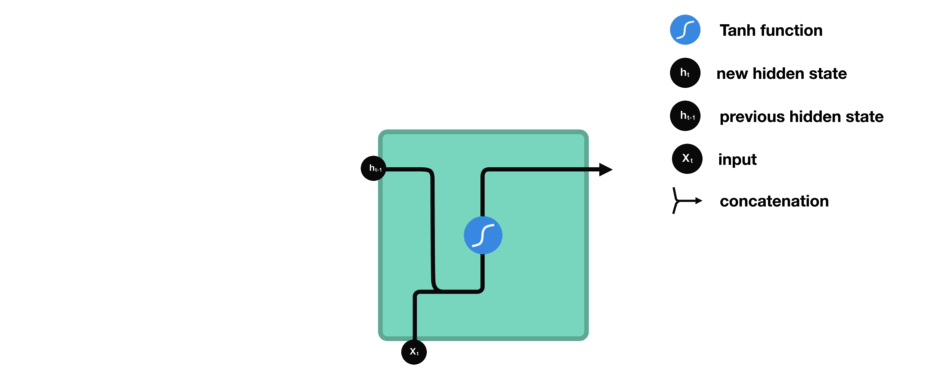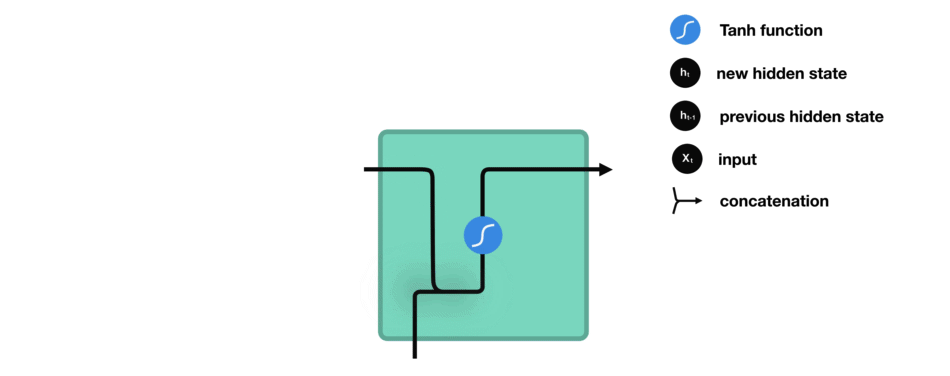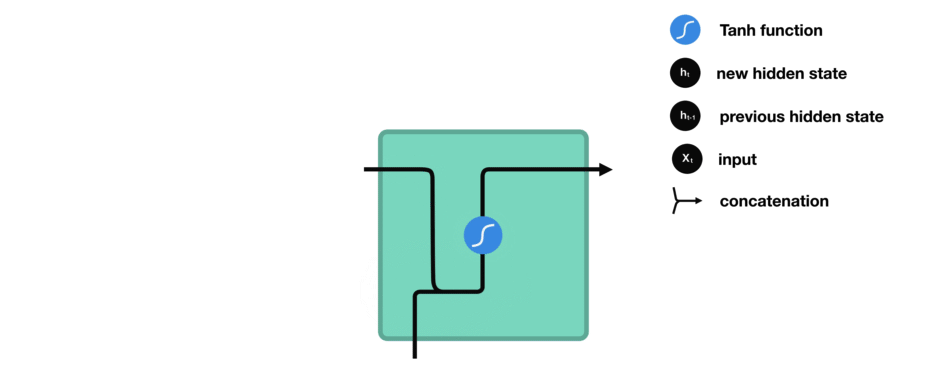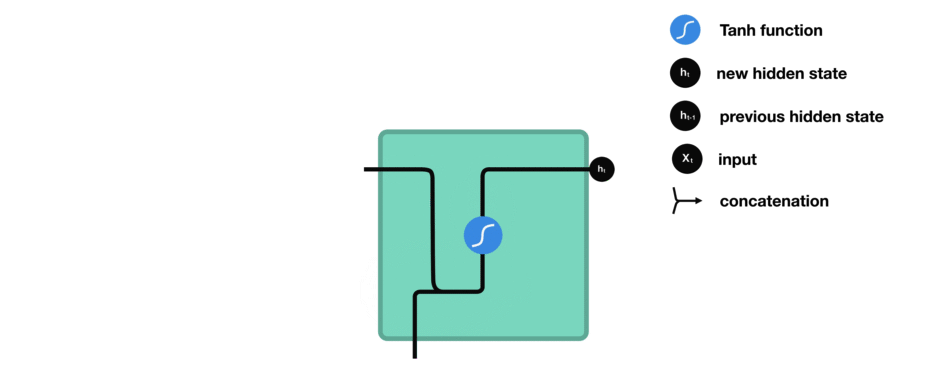
RNN
- 이전 출력과 새로운 입력이 결합되어 벡터를 형성하고, 벡터는 tanh()를 거쳐 출력이 된다.
LSTM
- RNN과 유사하지만 셀 내부 운영방식이 다르다.
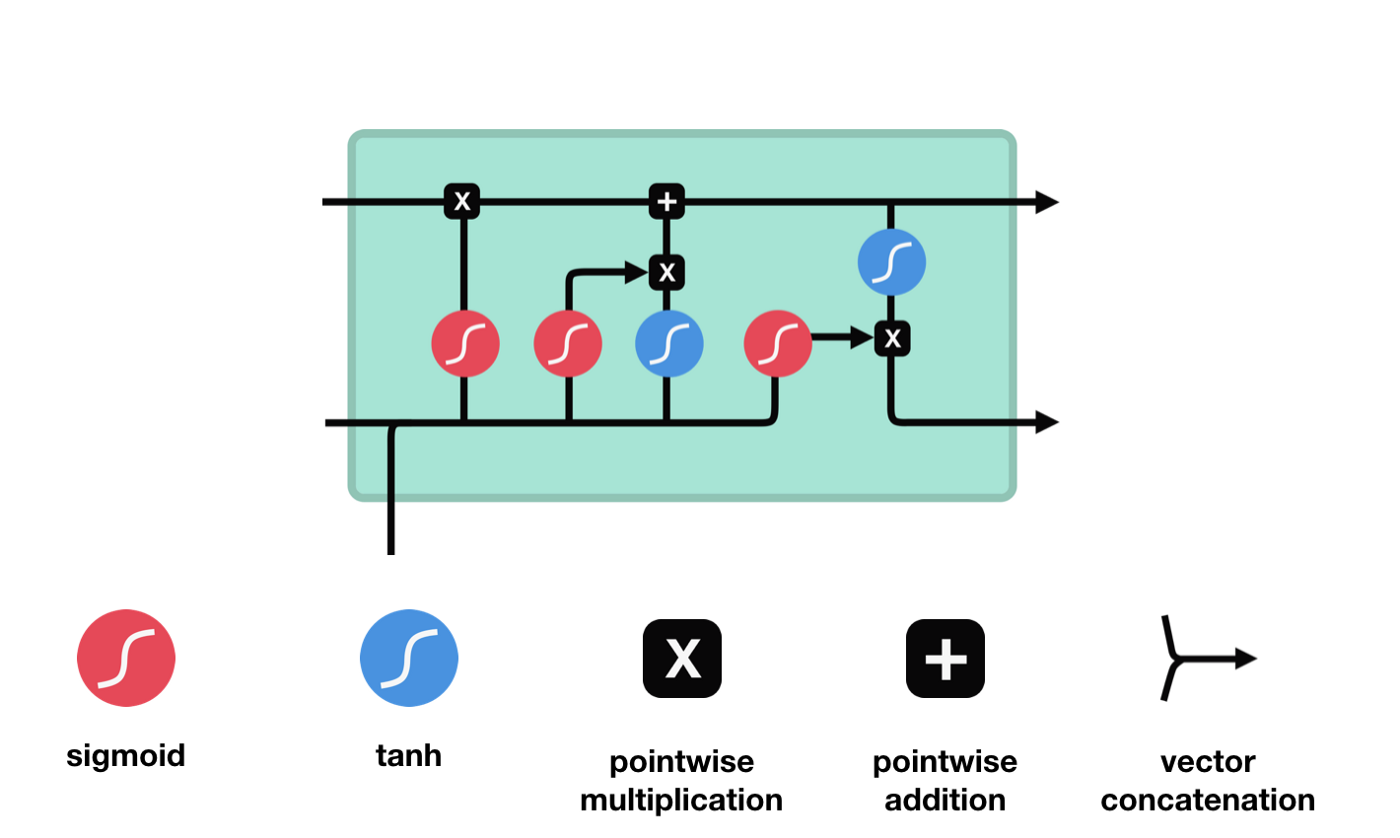
3. LSTM의 활성화 함수
LSTM 네트워크는 3개의 sigmoid, 2개의 tanh 함수로 구성되어 있다.
tanh()
-1 ~ 1- 정보의 강약 정도
- 다음 단계에 얼마나 중요한가를 조정
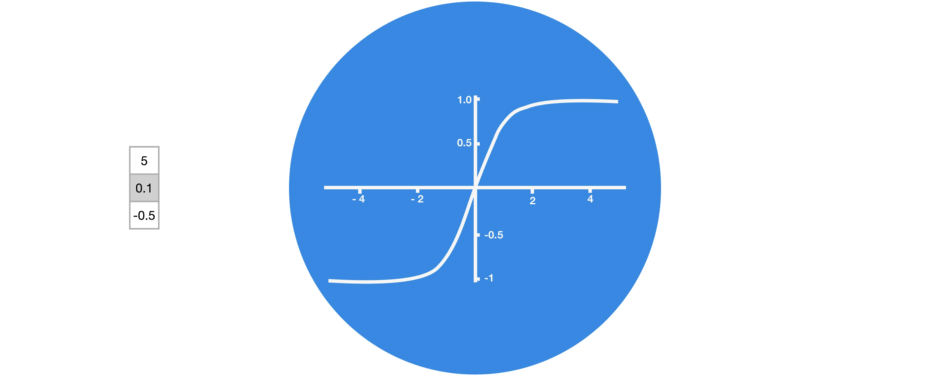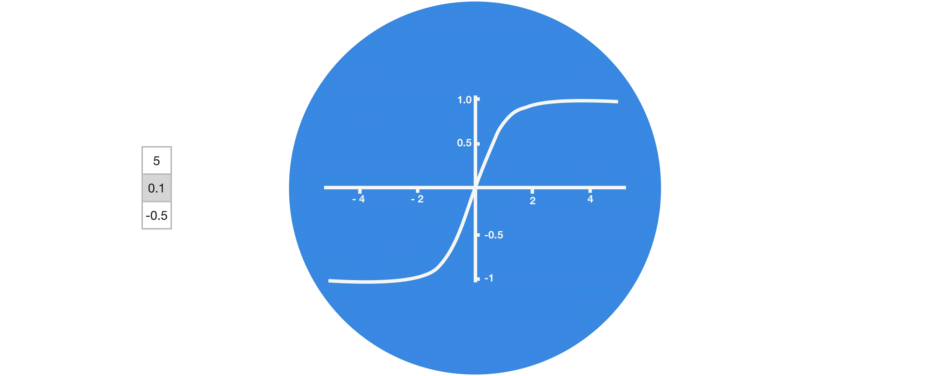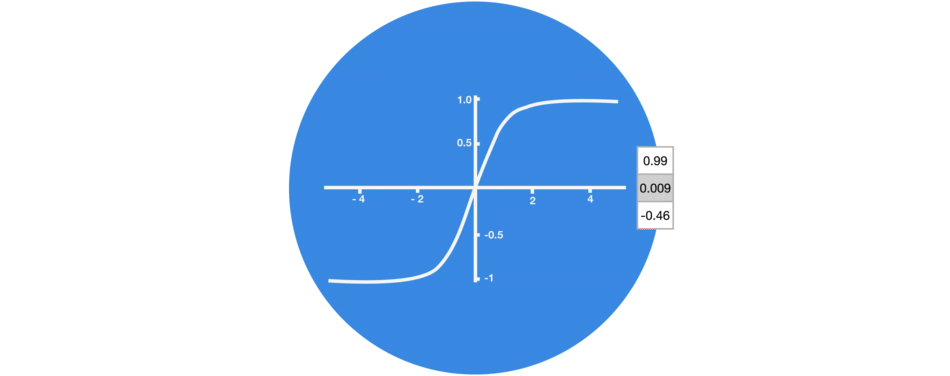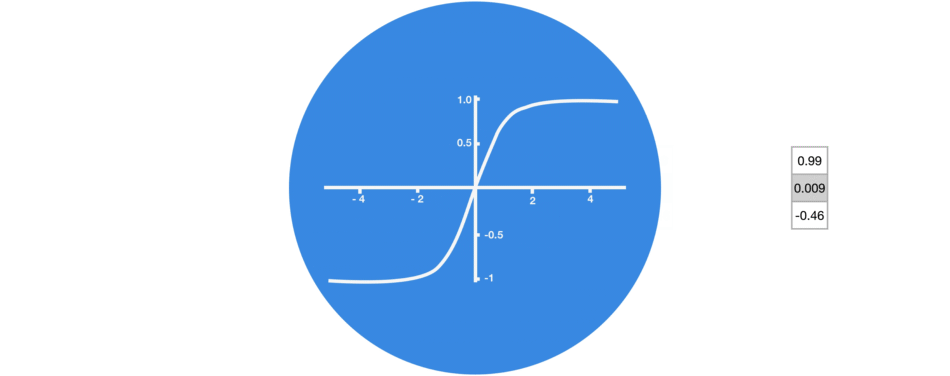
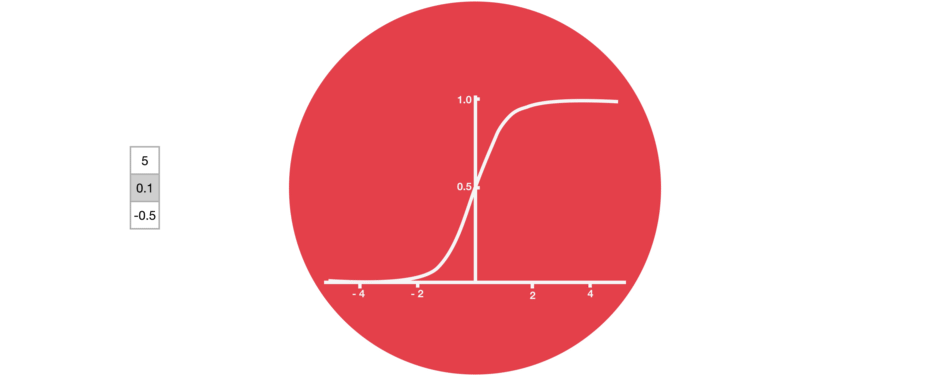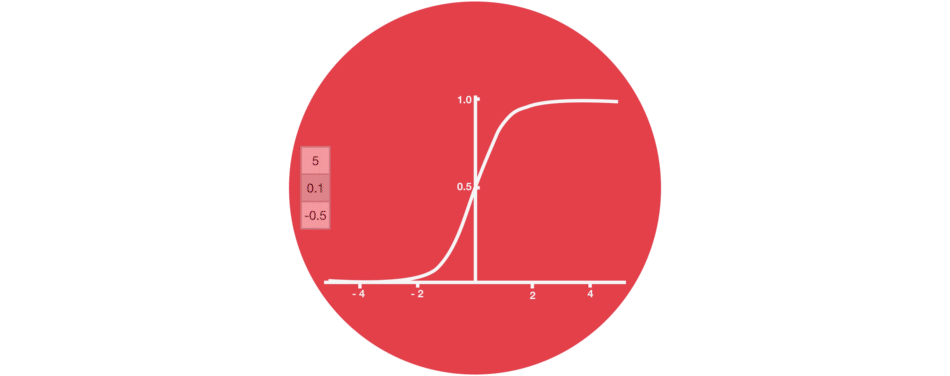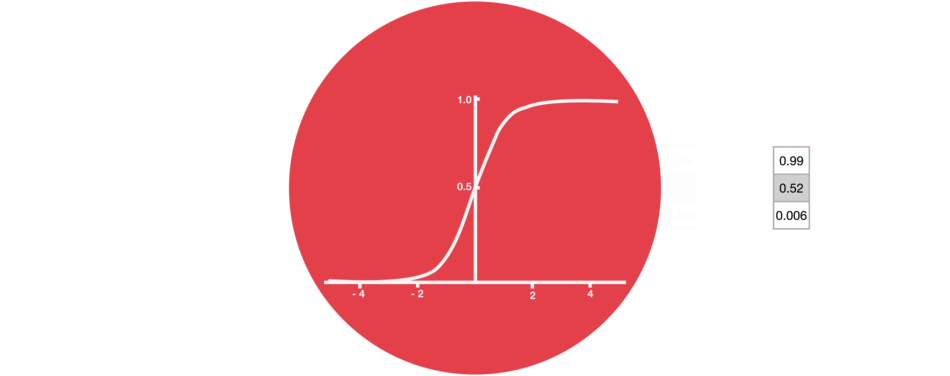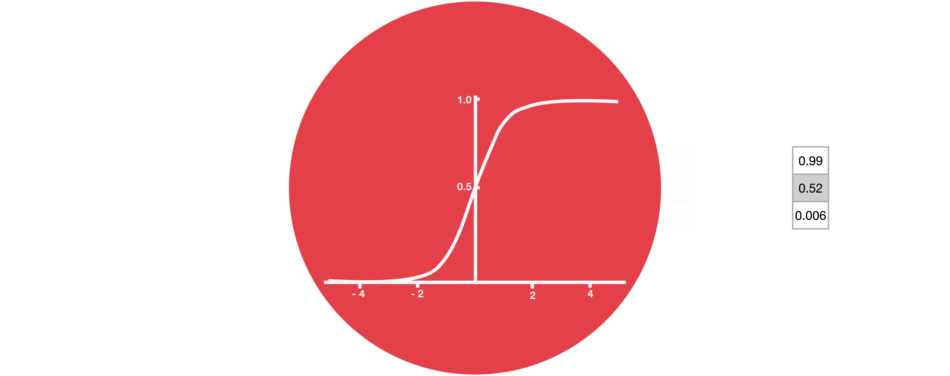
sigmoid()
0 ~ 1- 정보의 반영 비율
- 다음 단계에 얼마나 반영할지(= 정보를 얼마나 버릴지)를 조정
- 0이면 정보를 반영하지 않고, 1이면 정보를 모두 반영하는 것
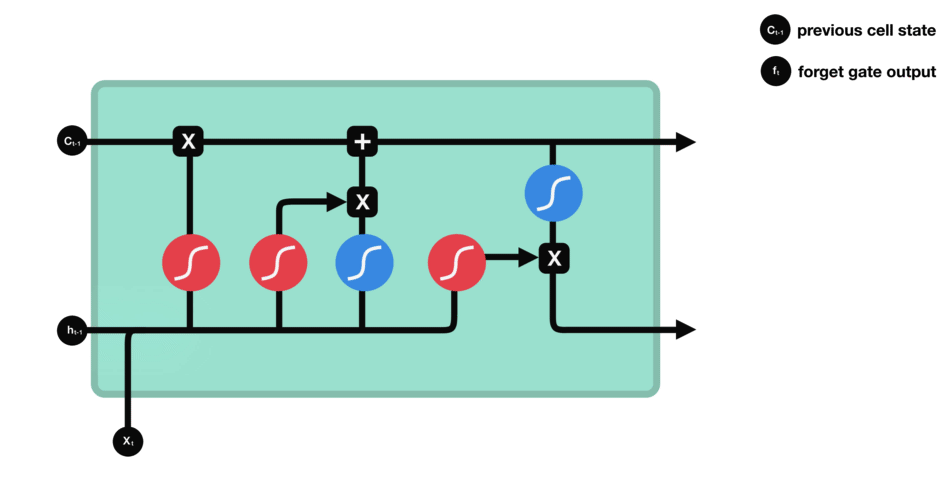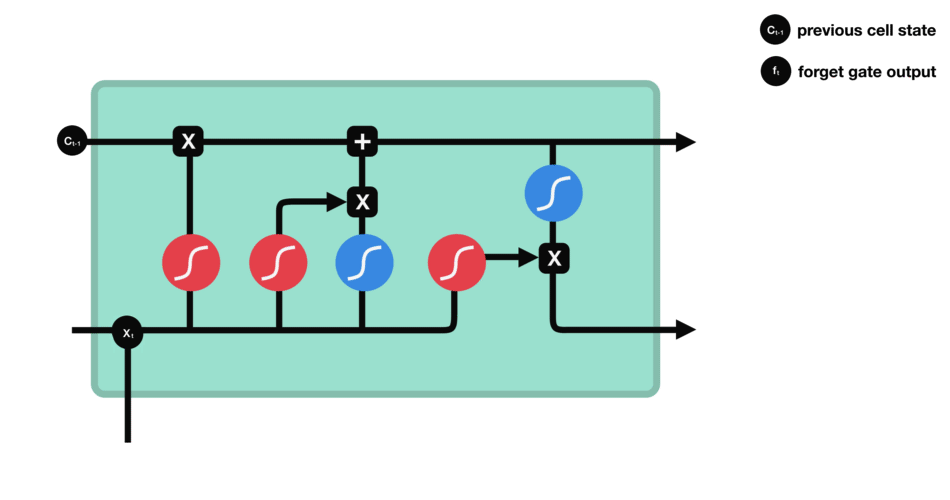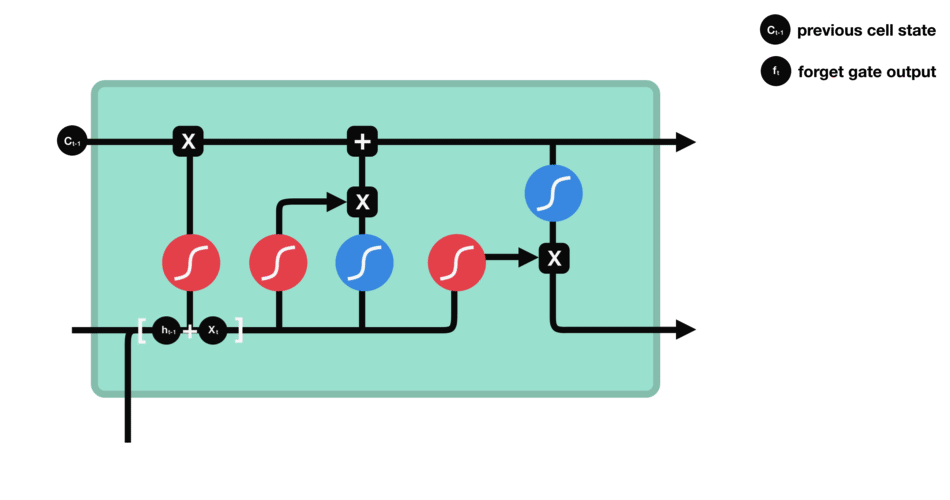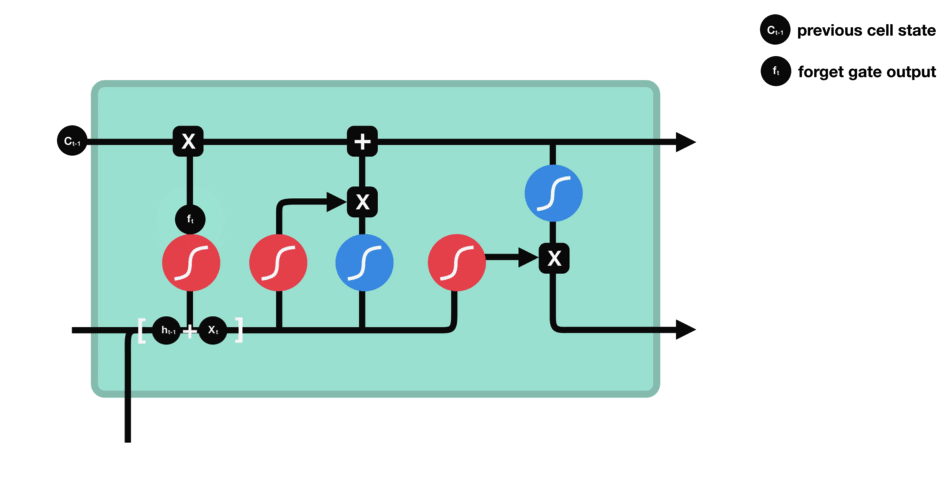
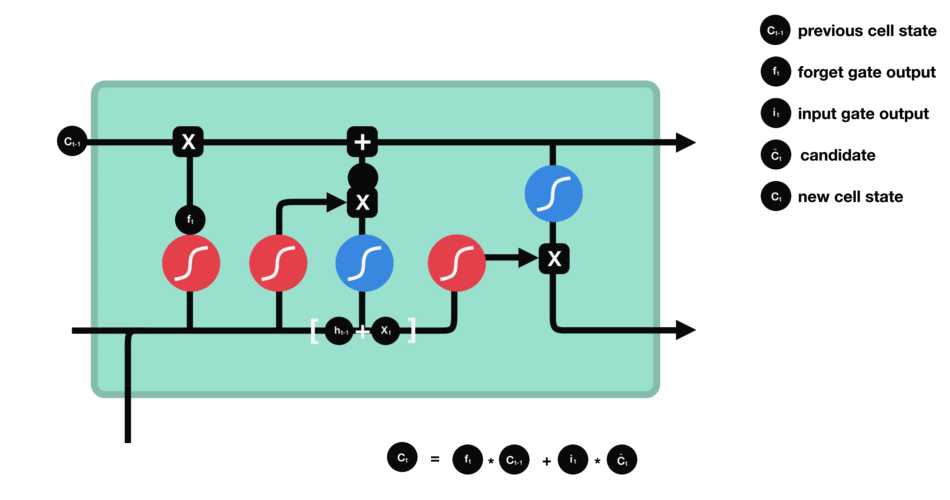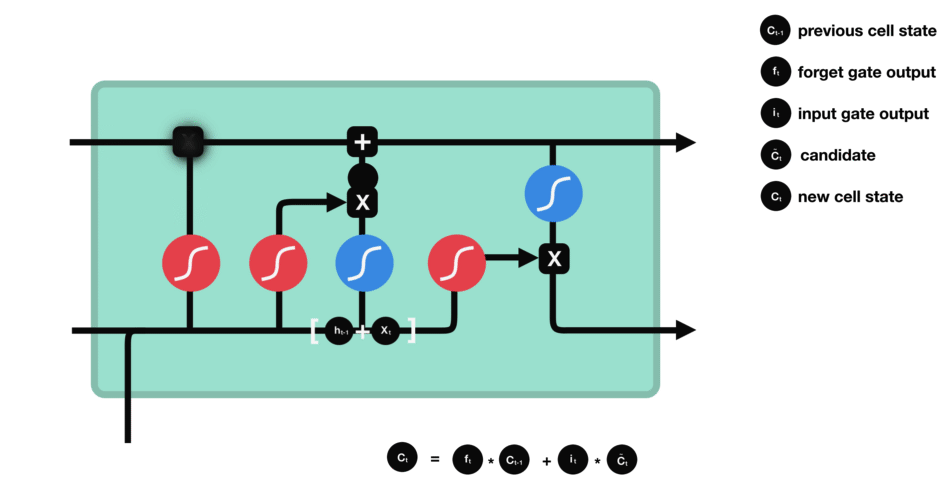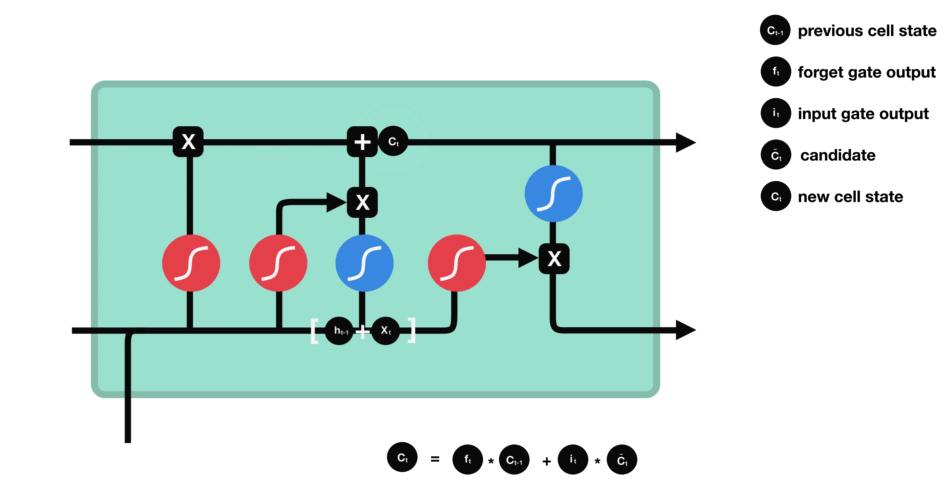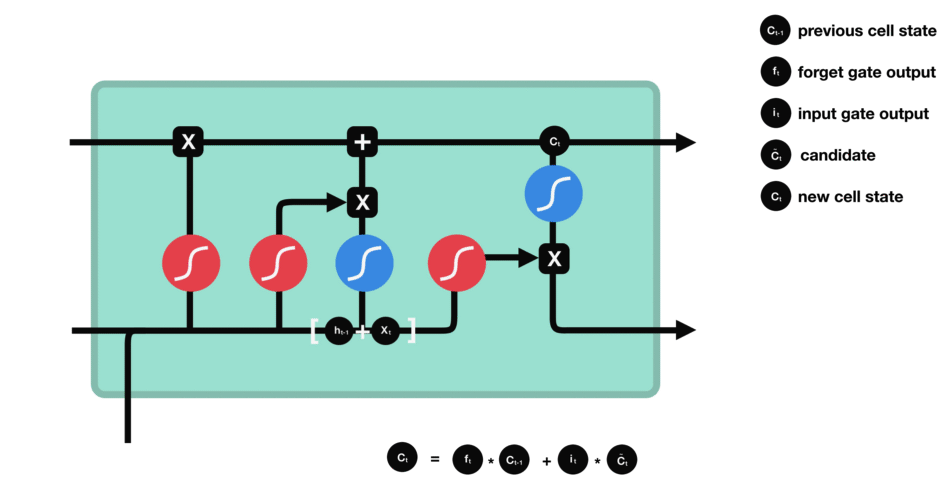
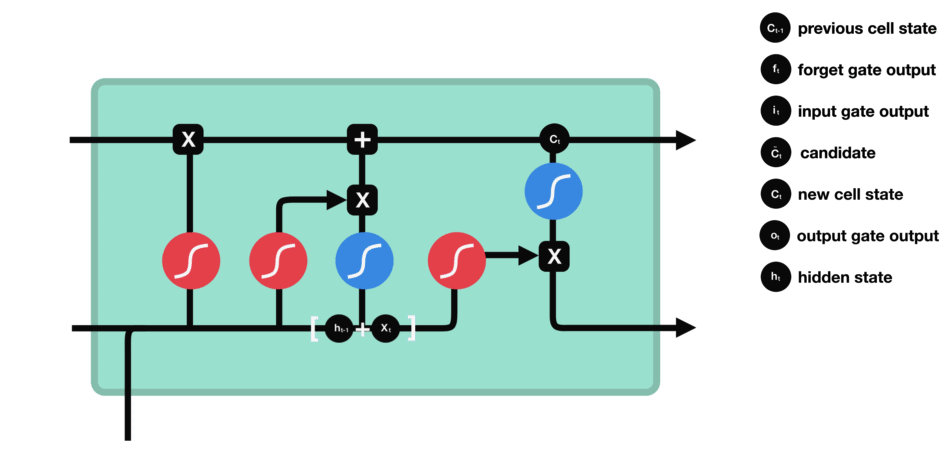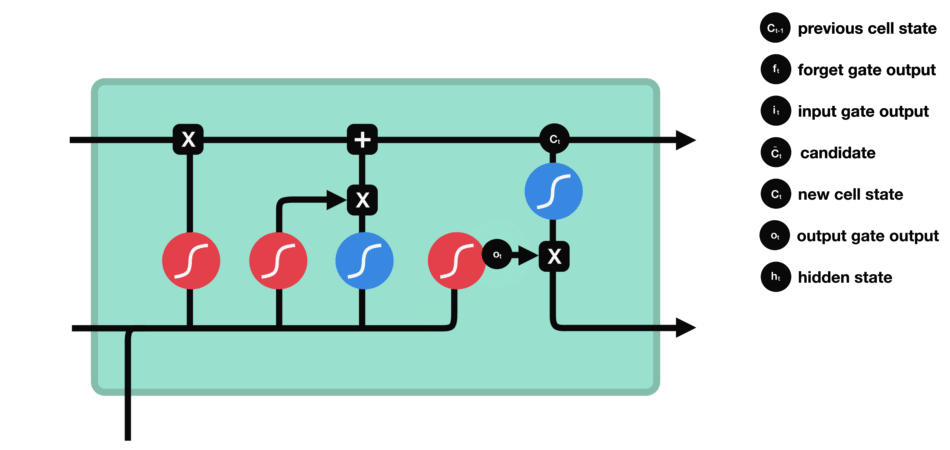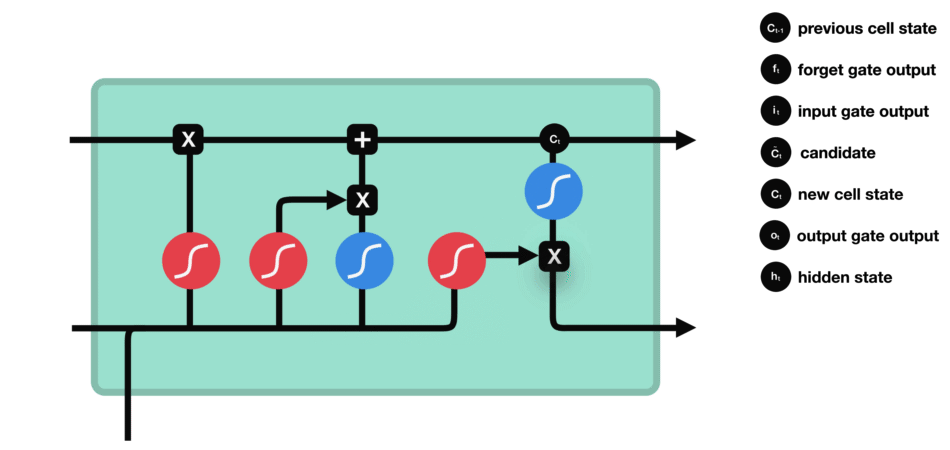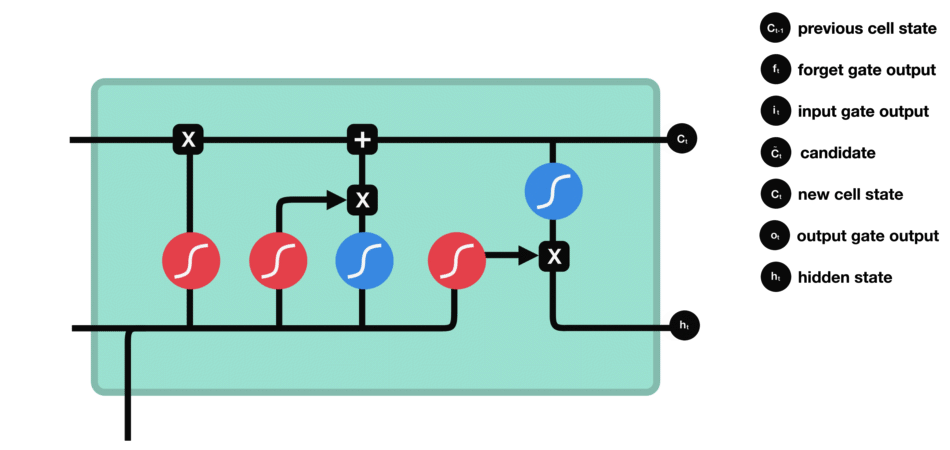
4. LSTM의 Gate
LSTM 네트워크는 4개의 Gate로 이루어져 있다.
forget gate
- 새로운 정보($h_{t-1},x_t$)를 사용하여 과거의 정보($C_{t-1}$) 중 어떤 정보를 버릴지 정하는 기능
- sigmoid()를 사용하게되면 0 ~ 1의 값이 되므로, $C_{t-1}$을 얼마나 버릴지 결정할 수 있다.
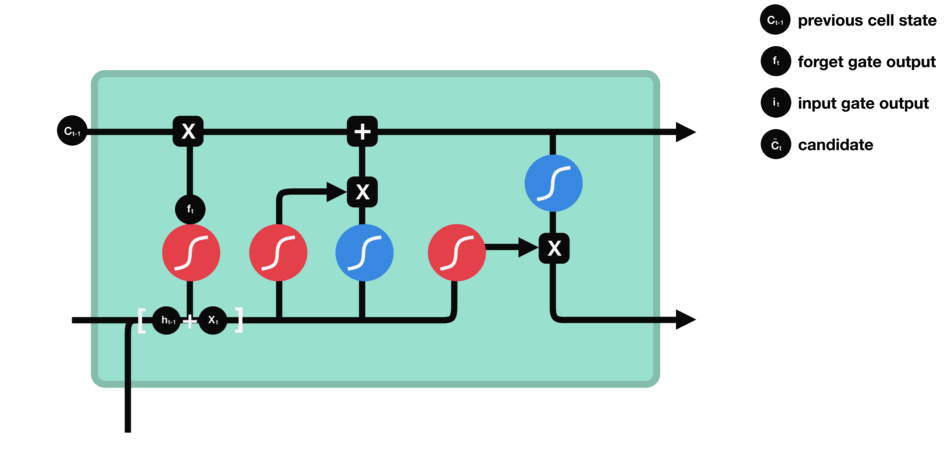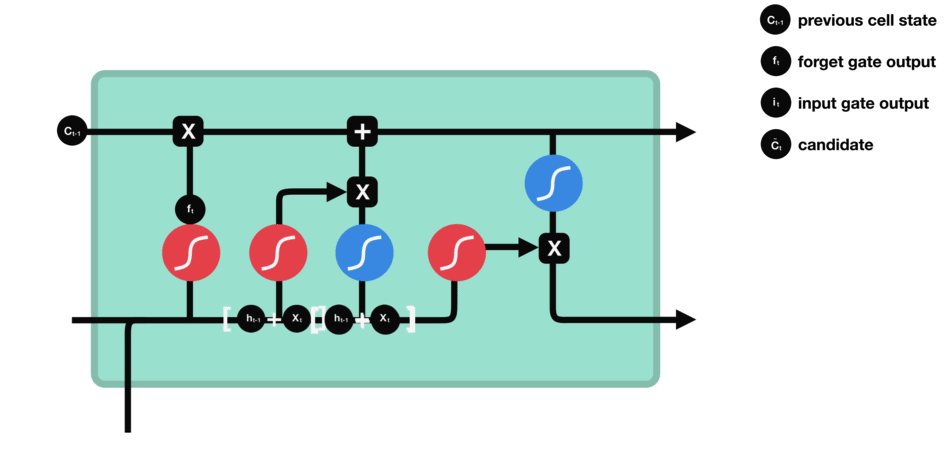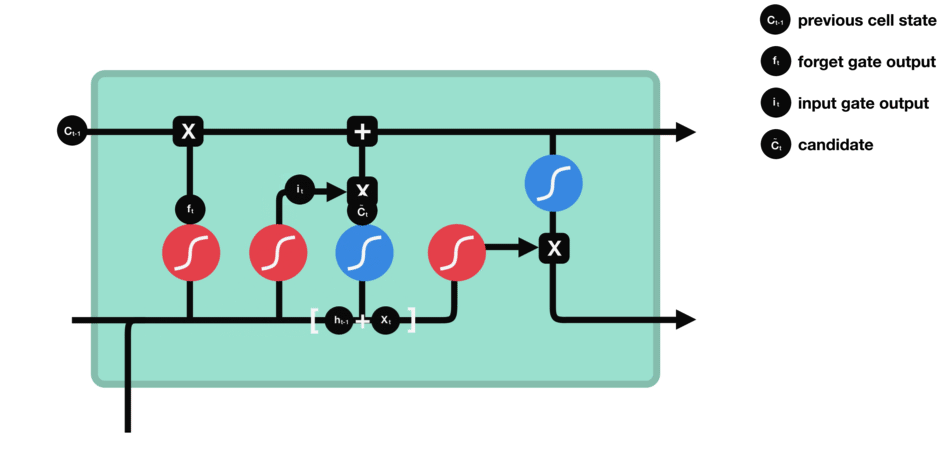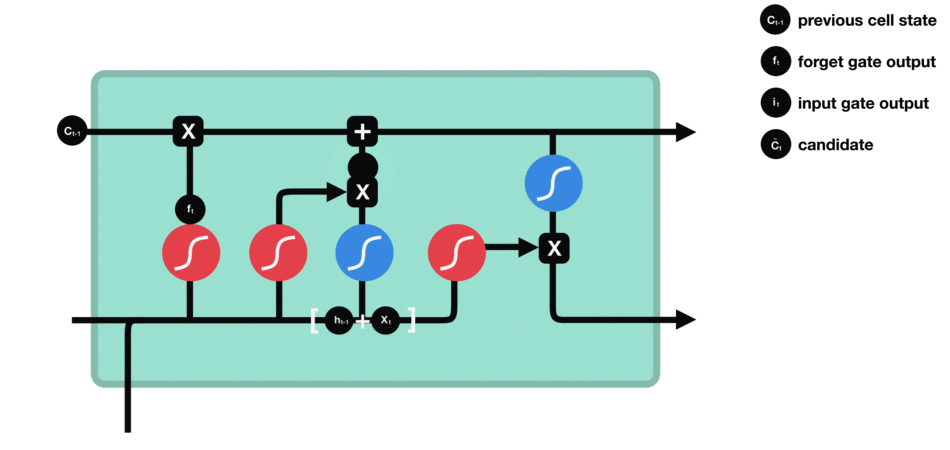
input gate
- 새로운 정보($h_{t-1},x_t$) 중 어떤 것을 Memory Cell에 저장할지 정하는 기능
- sigmoid()에 의해 어떤 값을 업데이트할 지 결정하고, tanh()에 의해 유지해야할 중요한 정보를 결정한다.
cell state
- 과거 Memory Cell의 상태($C_{t-1}$)를 업데이트하여($C_t$) 다음 Memory Cell에 전달하는 기능
output gate
- 어떤 정보를 출력($h_t$)해야할지 정하는 기능
- 새로운 정보($h_{t-1},x_t$)와 업데이트된 Memory Cell의 상태를 곱하여 어떤 정보를 전달할지 결정한다.
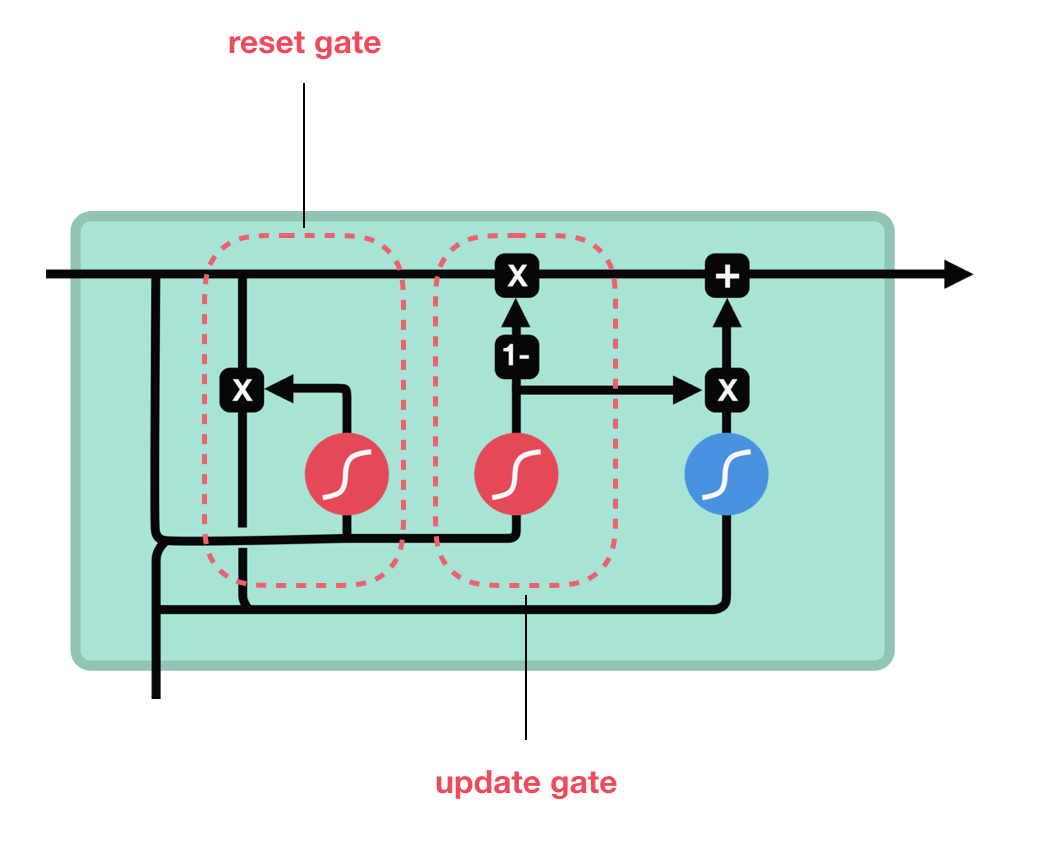
5. GRU(Gated Recurrent Unit)
LSTM이 간소화된 버전
GRU는 LSTM에서 사용된 연산을 중첩시켜 간소화 시킨 알고리즘이다.
훈련 속도는 LSTM보다 빠르지만, 성능은 떨어진다.
References
- https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
Leave a comment