
[Deep Learning] 과적합(Overfitting) 해결
과적합(Overfitting)
모델이 Train Data에만 최적화되어 Validation Data에는 성능이 떨어지는 상태
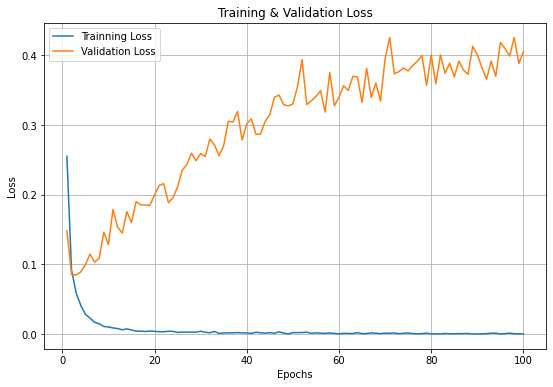
1) 과적합의 원인
(1) 학습 데이터 부족
(2) Model Capacity가 높을 때(= 파라미터 개수가 많을 때)
2) DNN에서 과적합을 해결하는 방법
여러가지 방법이 있으며 하나의 방법만 사용하는 것이 아니라,
조합해서 사용할 수 있다.
(1) 더 많은 Train Data
Data points를 추가로 획득하는 방법
(2) Model Capacity
Hidden Layer, Node 수를 줄이는 방법
-
코드
from keras import models, layers mnist_MC = models.Sequential() # mnist_MC.add(layers.Dense(512, activation = 'relu', input_shape = (28 * 28,))) mnist_MC.add(layers.Dense(256, activation = 'relu', input_shape = (28 * 28,))) # 노드 개수 줄이기 # mnist_MC.add(layers.Dense(256, activation = 'relu')) # 삭제 mnist_MC.add(layers.Dense(10, activation = 'softmax'))
(3) L2 Regularization
가중치의 제곱에 비례하는 노이즈를 오차 함수에 추가하는 방법(가중치 감쇠로 인한 가중치 차수 감소)
-
코드
from keras import models, layers from keras import regularizers mnist_L2 = models.Sequential() mnist_L2.add(layers.Dense(512, activation = 'relu', kernel_regularizer = regularizers.l2(0.00001), input_shape = (28 * 28,))) mnist_L2.add(layers.Dense(256, activation = 'relu', kernel_regularizer = regularizers.l2(0.00001))) mnist_L2.add(layers.Dense(10, activation = 'softmax'))
(4) Dropout
훈련 과정에서 네트워크의 일부를 생략하는 방법(Fully connected와 반대 개념)
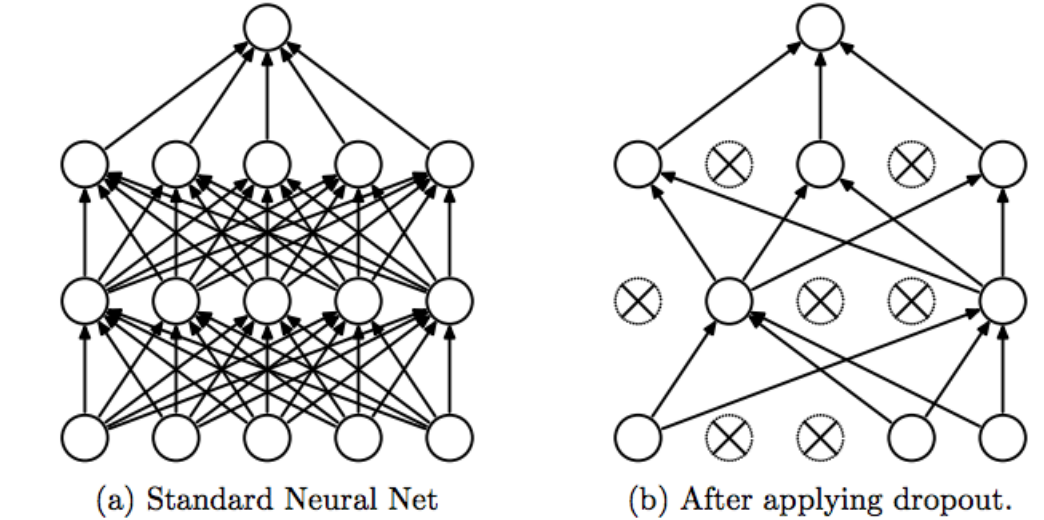
Srivastava, Nitish, et al. ”Dropout: a simple way to prevent neural networks from overfitting”, JMLR 2014
-
Epoch 마다 Drop되는 Node들이 무작위로 바뀐다.
-
코드
from keras import models, layers mnist_DO = models.Sequential() mnist_DO.add(layers.Dense(512, activation = 'relu', input_shape = (28 * 28,))) mnist_DO.add(layers.Dropout(0.5)) mnist_DO.add(layers.Dense(256, activation = 'relu')) mnist_DO.add(layers.Dropout(0.5)) mnist_DO.add(layers.Dense(10, activation = 'softmax'))
(5) Batch Normalization
활성화 함수의 입력값을 정규화 과정을 수행하여 전달하는 방법
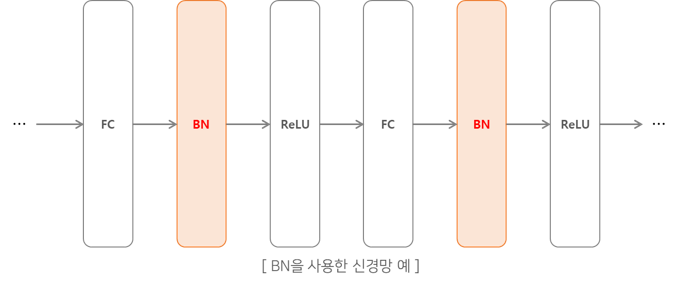
https://excelsior-cjh.tistory.com/178
- 최근 가장 많이 적용되고 있는 방법 중 하나
- 일반적으로 Fully Connected나 Convolutional layer 바로 다음과 활성화 함수를 사이에 레이어를 삽입하여 사용함
- Input data는 정규분포라고 하더라도 레이어를 거치고나면 정규분포가 아닐 수도 있다.
- 따라서 data를 정규화하여 활성화 함수를 통과하게 한다.
- Gradient Vanishing 문제(미분값이 0이되는 문제) 해결을 가능하게 함
- 분포를 변경하면, 미분했을 때 0이 되지 않기 때문
- 더 큰 학습률을 사용할 수 있게 함
-
Batch Normalization을 적용하면 학습을 위한 파라미터($\mu,\ \sigma$)가 추가된다.
-
코드
from keras import models, layers mnist_BN = models.Sequential() mnist_BN.add(layers.Dense(512, input_shape = (28 * 28,))) mnist_BN.add(layers.BatchNormalization()) mnist_BN.add(layers.Activation('relu')) mnist_BN.add(layers.Dense(256)) mnist_BN.add(layers.BatchNormalization()) mnist_BN.add(layers.Activation('relu')) mnist_BN.add(layers.Dense(10, activation = 'softmax'))
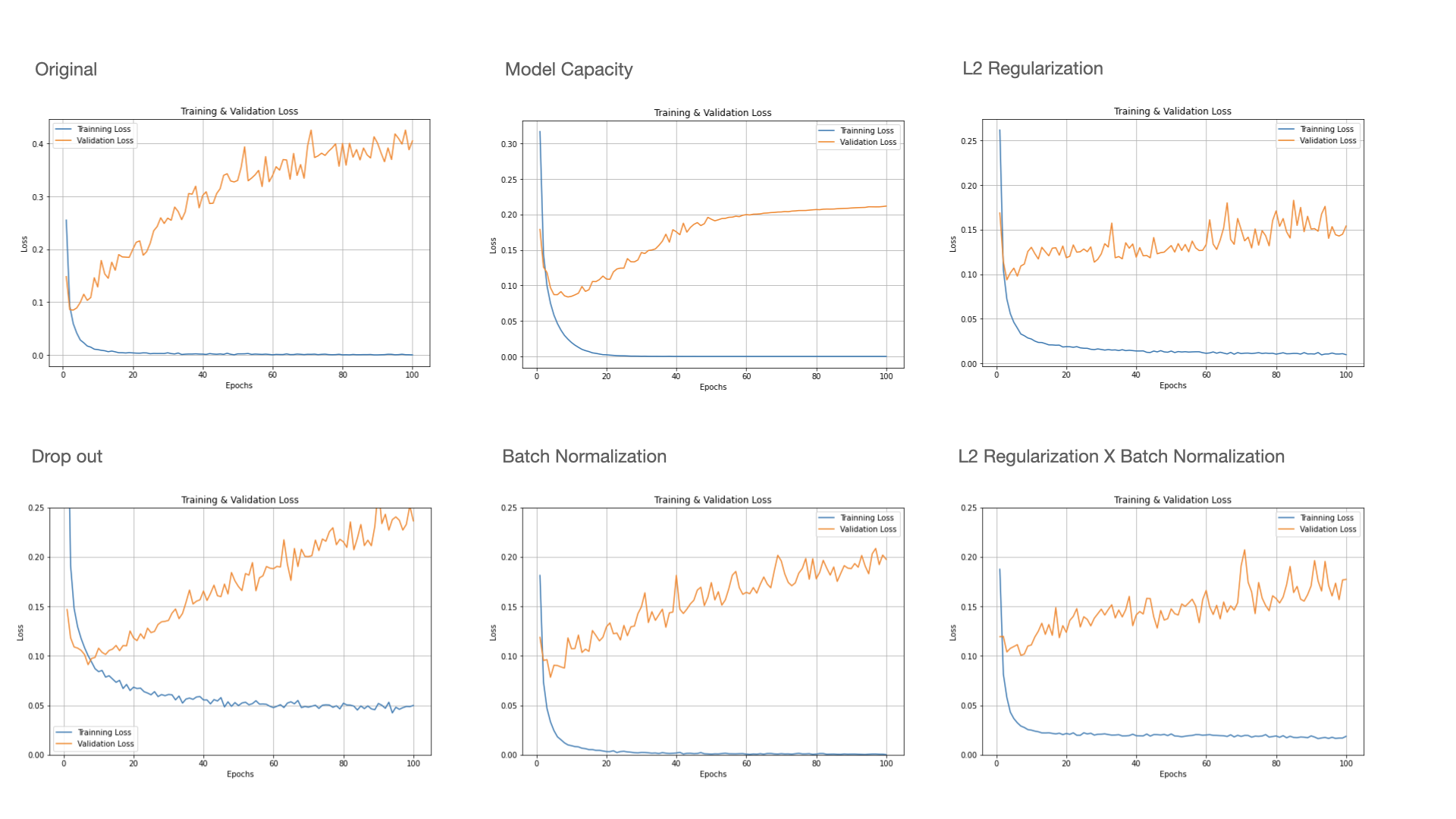
3) 예시 : 과적합 해결 방법 비교
Leave a comment