
[Deep Learning] 변이형 오토인코더(Variational AutoEncoder)
1. 변이형 오토인코더(Variational AutoEncoder, VAE)
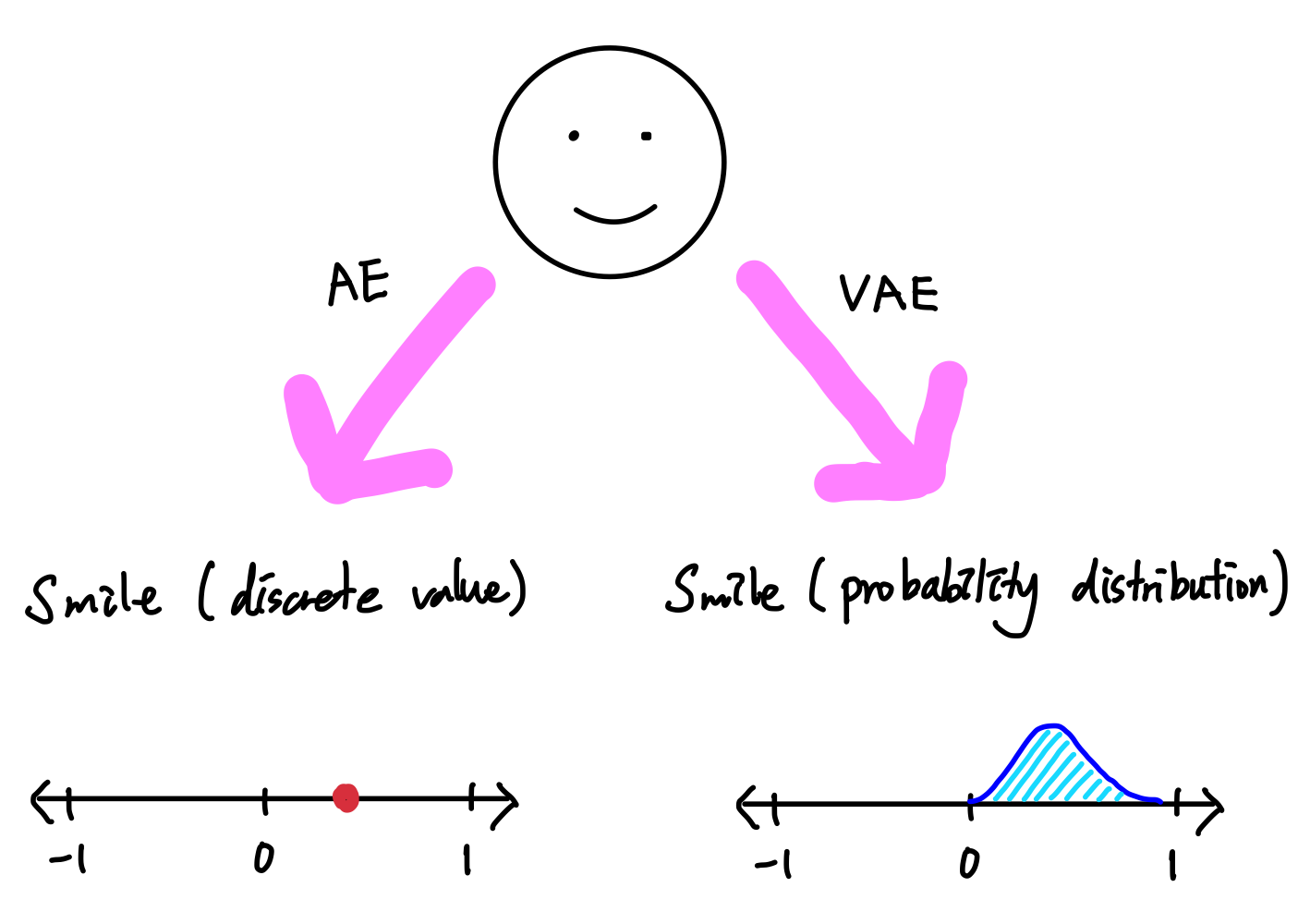
오토인코더(AutoEncoder, AE)는 잠재 공간의 값을 고정된 값(표현 벡터)으로 나타냈지만
변이형 오토인코더(VAE)는 잠재 공간의 값을 가우시안 확률분포(정규분포) 값의 범위로 제공한다.
즉, 잠재 공간의 값은 평균과 분산으로 매핑된다.
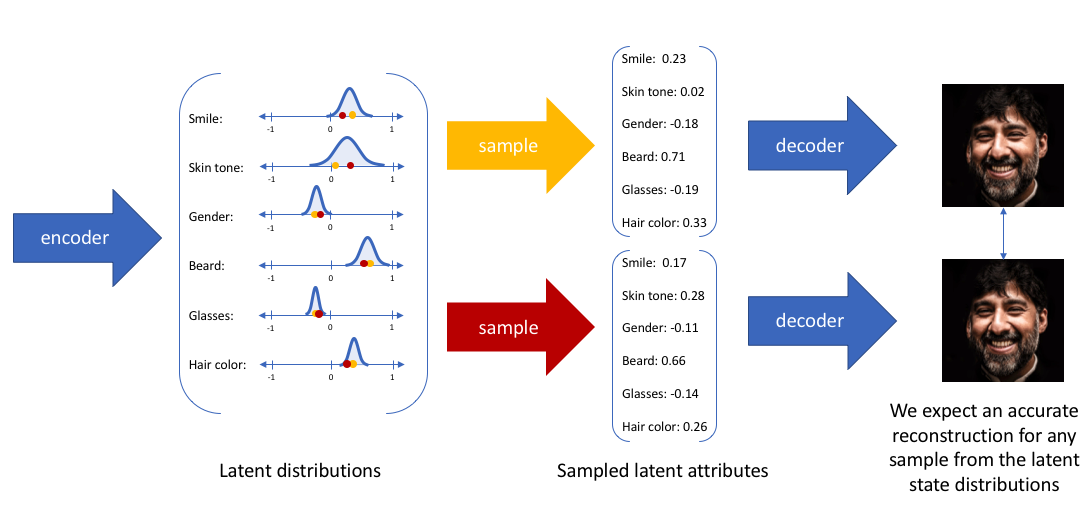
이미지로 예를 들자면(텍스트도 가능하다),
인코더를 통해 이미지로부터 분포를 학습시키고, 분포로부터 값을 랜덤 샘플링하면 원래 값과 약간 다른 값이 나오게 된다.
VAE는 이러한 방식으로 값을 조절하여 원본 이미지로부터 원본 처럼 생긴 이미지를 생성(Generate)한다.
VAE는 인코더를 학습시키는 AE와 달리 디코더(생성되는 부분)를 학습시키는 것이 목적이다.
AE의 인코더 파트를 사용하여 분포(평균과 분산)를 뽑아내고
분포로부터 랜덤 샘플링된 값(z)을 가지고 디코더(=Generator)로 복원하여 새로운 이미지가 생성되도록 학습을 시키는 것이다.
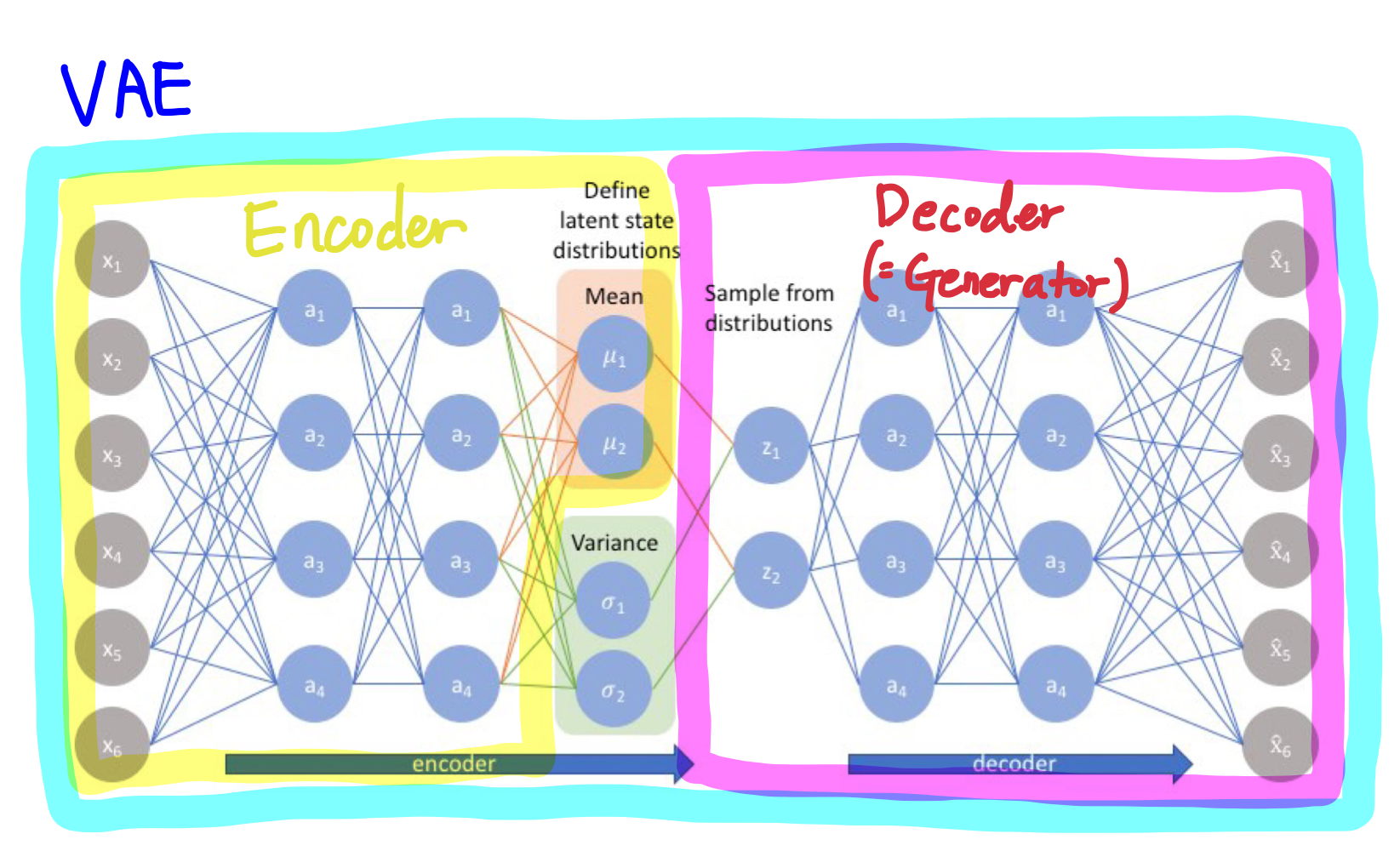
랜덤 샘플링된 값(z)를 얻기 위해 평균에 분산을 더하게 되는데
분산은 정규 분포에서 랜덤하게 뽑아낸 값($\epsilon$, epsilon)을 곱하여 사용한다.
VAE는 학습할 때 인코더, 디코더 별로 목표가 달라서 학습에 사용되는 Loss가 2개 이다.
2개의 Loss는 더하여 학습에 사용된다.
Reconstruction Loss
Decoder의 Loss
- 원본 이미지와 생성된 이미지와의 오차(CEE)
- ‘샘플링 함수’로 생성한 ‘z’ 값으로 얼마나 원본이미지와 유사한 이미지를 잘 생성 하는가?
KL Loss
Encoder의 Loss
- 사전 분포와 잠재 분포 사이의 Kullback Leibler-Divergence(두 확률분포 간 거리)
- 사전 분포(Prior Distribution) : 원본 이미지 확률분포
- 잠재 분포(Latent Distribution) : 잠재공간 확률분포
- ‘샘플링 함수’의 값(z)이 원본 이미지의 확률분포와 유사한가?
References
- https://www.jeremyjordan.me/variational-autoencoders/
Leave a comment