
[Django] 파이썬 웹 표준 라이브러리
2. 웹 표준 라이브러리
2.1 웹 라이브러리 구성
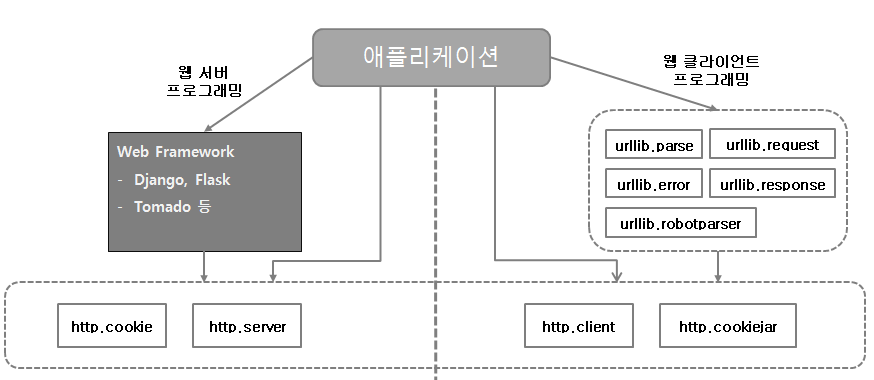
2.2 웹 클라이언트 라이브러리
웹 클라이언트를 위한 파이썬 표준 라이브러리가 있지만, 실제 프로젝트에서는 외부 라이브러리인 requests, beautifulsoup4 등을 사용함
2.2.1 urllib.parse 모듈
URL의 분해, 조립, 변경 및 URL 문자 인코딩, 디코딩 등 처리하는 함수 제공
-
urlparse()
from urllib.parse import urlparse result = urlparse("http://www.python.org:80/guido/python.html;philosophy?overall=3#n10") print(result) # ParseResult(scheme='http', netloc='www.python.org:80', path='/guido/python.html', params='philosophy', query='overall=3', fragment='n10')- schema : 프로토콜
- netloc : 네트워크 위치, host:port
- path : 파일 또는 애플리케이션 경로
- params : 애플리케이션에 전달될 매개변수
- query : 질의 문자열 또는 매개변수, &로 구분된 이름=값 쌍 형식
- fragment : 문서 내 앵커 등 조각
2.2.2 urllib.request 모듈
URL에서 데이터를 가져오는 기본 기능 제공 제공
-
urlopen()
-
Default 요청 방식 : GET
-
사용 케이스 사용 방법 URL로 GET/POST 방식의 간단한 요청 처리 urlopen() PUT, HEAD 메소드 등 헤더 조작이 필요한 경우 Request 클래스를 같이 사용 인증, 쿠키, 프록시 등 복잡한 요청 처리 인증/쿠키/프록시 해당 핸들러 클래스를 같이 사용
-
2.2.3 urllib.request 모듈 예제
from urllib.request import urlopen
from html.parser import HTMLParser
class ImageParser(HTMLParser):
def handle_starttag(self, tag, attrs):
if tag != 'img':
return
if not hasattr(self, 'result'):
self.result = []
for name, value in attrs:
if name == 'src':
self.result.append(value)
def parse_image(data):
parser = ImageParser()
parser.feed(data)
dataSet = set(x for x in parser.result)
return dataSet
def main():
url = "http://www.google.co.kr"
with urlopen(url) as f:
charset = f.info().get_param('charset')
data = f.read().decode(charset)
dataSet = parse_image(data)
print("\n>>>>>>>>> Fetch Images from", url)
print('\n'.join(sorted(dataSet)))
if __name__ == '__main__':
main()
'''
>>>>>>>>> Fetch Images from http://www.google.co.kr
/images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png
/textinputassistant/tia.png
'''
2.2.4 http.client 모듈
대부분의 웹 클라이언트 프로그램은 urllib.request 모듈에 정의된 기능만으로 작성 가능함
urllib.request 모듈로는 쉽게 처리할 수 없는 경우, http.client 모듈을 사용함
- GET, POST 이외의 방식으로 요청을 보내거나, 요청 헤더와 바디 사이에 타이머를 두어 시간을 지연시키는 등, …
urllib.request 모듈로 작성한 로직은 http.client 모듈을 사용해도 동일하게 작성 가능
http.client 모듈 사용 시 코딩 순서
- 연결 객체 생성(
conn = http.client.HTTPConnection("www.python.org")) - 요청을 보냄(
conn.request("GET", "/index.html") - 응답 객체 생성(
response = conn.getresponse()) - 응답 데이터를 읽음(
data = response.read()) - 연결을 닫음(
conn.close())
2.2.5 http.client 모듈 예제
import os
from http.client import HTTPConnection
from urllib.parse import urljoin, urlunparse
from urllib.request import urlretrieve
from html.parser import HTMLParser
class ImageParser(HTMLParser):
def handle_starttag(self, tag, attrs):
if tag != 'img':
return
if not hasattr(self, 'result'):
self.result = []
for name, value in attrs:
if name == 'src':
self.result.append(value)
def download_image(url, data):
if not os.path.exists('DOWNLOAD'):
os.makedirs('DOWNLOAD')
parser = ImageParser()
parser.feed(data)
dataSet = set(x for x in parser.result)
for x in sorted(dataSet) :
imageUrl = urljoin(url, x)
basename = os.path.basename(imageUrl)
targetFile = os.path.join('DOWNLOAD', basename)
print("Downloading...", imageUrl)
urlretrieve(imageUrl, targetFile)
def main():
host = "www.google.co.kr"
conn = HTTPConnection(host)
conn.request("GET", '')
resp = conn.getresponse()
charset = resp.msg.get_param('charset')
data = resp.read().decode(charset)
conn.close()
print("\n>>>>>>>>> Download Images from", host)
url = urlunparse(('http', host, '', '', '', ''))
download_image(url, data)
if __name__ == '__main__':
main()
'''
>>>>>>>>> Download Images from www.google.co.kr
Downloading... http://www.google.co.kr/images/branding/googlelogo/1x/googlelogo_white_background_color_272x92dp.png
Downloading... http://www.google.co.kr/textinputassistant/tia.png
'''
2.3 웹 서버 라이브러리
웹 프로그래밍의 클라이언트쪽은 웹 브라우저라는 강력한 프로그램을 사용하기 때문에, 웹 프로그래밍이라고 하면 보통은 서버쪽 프로그래밍으로 인식하는 경우가 많음
웹 서버 프로그램을 작성할 때 ‘웹 프레임 워크‘를 사용해서 개발하는 경우가 대부분
- 프레임워크 : 개발자가 웹 서버 프로그램을 개발하기 쉽도록 저수준의 기능을 이미 만들어 놓은 기반 프로그램 개발자는 프레임워크를 활용하여 응용 로직만 개발하면 되므로, 훨씬 효율적임
웹 서버 클래스
서버를 만들기 위해서는 HTTPServer 및 BaseHTTPRequestHandler 기반 클래스를 임포트하거나 상속받아야함 HTTP 프로토콜을 처리해주는 기능은 별도로 코딩할 필요가 없음
모든 HTTP 웹 서버는 BaseHTTPServer 모듈의 HTTPServer 클래스를 사용하여 작성하고, 웹 서버에 사용되는 핸들러는 BaseHTTPServer 모듈의 BaseHTTPRequestHandler를 상속받아 작성
2.3.1 간단한 웹 서버
- 웹 클라이언트로부터 요청을 받고 “Hello World”라는 문장을 되돌려주는 아주 간단한 웹 서버
from http.server import HTTPServer, BaseHTTPRequestHandler
class MyHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response_only(200, 'OK')
self.send_header('Content-Type', 'text/plain')
self.end_headers()
self.wfile.write(b"Hello World")
if __name__ == '__main__':
server = HTTPServer(('', 8888), MyHandler)
print("Started WebServer on port 8888...")
print("Press ^C to quit WebServer.")
server.serve_forever()
'''
Hello World
'''
2.4 CGI/WSGI 라이브러리
https://blog.neonkid.xyz/249
CGI(Common Gateway Interface)
웹 서버가 사용자의 요청을 애플리케이션에 전달하고 애플리케이션의 처리 결과를 애플리케이션으로부터 되돌려받기 위한, 즉 웹 서버와 애플리케이션 간에 데이터를 주고받기 위한 규격
웹 서버와 외부 프로그램을 연결해주는 표준화된 프로토콜

FastCGI
CGI 방식은 클라이언트의 요청이 발생할 때마다 프로세스를 추가로 생성하고 삭제하게 되므로, 다수의 사용자가 동시에 요청할 경우 오버헤드가 심해지고, 성능 저하의 원인이 됨
FastCGI는 몇 번의 요청이 들어와도 하나의 프로세스만을 가지고 처리하게 되므로, 오버헤드가 월등하게 감소함
- Overhead(오버헤드) : 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 · 메모리 등
WSGI
파이썬 애플리케이션, 스크립트가 웹 서버와 통신하기 위한 인터페이스
웹 서버와 웹 애플리케이션을 연결해주는 규격
장고와 같은 파이썬 웹 프레임워크를 개발하거나, 이런 웹 프레임워크를 아파치와 같은 웹 서버와 연동할 때 사용함
CGI의 단점을 해결하고, 파이썬 언어로 애플리케이션을 좀 더 쉽게 작성할 수있도록 웹 서버와 웹 애플리케이션 간에 연동 규격을 정의한 것

https://medium.com/analytics-vidhya/what-is-wsgi-web-server-gateway-interface-ed2d290449e
Leave a comment