
[Machine Learning] 분류(Classification)
1. 분류(Classification)
1) 이진분류(Binary)
남자 vs 여자,정상 vs 비정상과 같이 데이터를 두 가지로(0 또는 1) 나누는 것
- 로지스틱 회귀로 이진분류가 가능함
2) 다중 분류(Categorical)
- 추후 학습 예정
- 소프트맥스 회귀 사용
2. Cross Entropy Error
분류에서 경사하강 시 사용하는 오차 함수
- 서로 다른 사건의 확률(Cross)을 곱하여 Entropy를 계산
- $y$ : 실제값, $\hat{y}$ : 예측값
- Entropy : 불순도
$-y \cdot log( \hat{y}) - (1-y) \cdot log(1- \hat{y})$
-
$y=0 \rightarrow -log(1- \hat{y})$

-
$y=1 \rightarrow -y \cdot log( \hat{y})$

3. Information Theory(정보 이론)
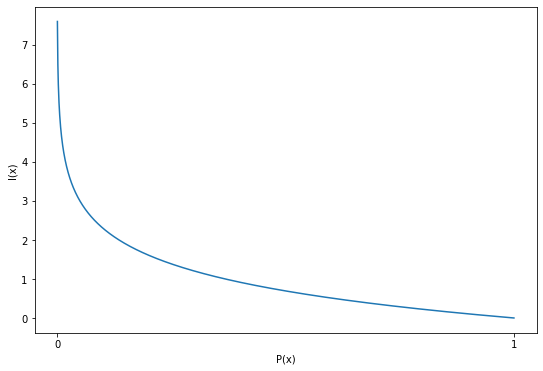
Information Theory
- 자주 발생하지 않는 사건(발생 확률이 적은, 0에 가까운)이 자주 발생하는 사건(발생 확률이 많은, 1에 가까운)보다 전달하는 정보량이 많음
- 정보 희귀성(발생가능성)의 반비례
- 예상하기 어려운 정보에 더 높은 가치를 매기기 때문에 Degree of Surprise(놀람의 정도)가 큼
$I(x)=-log(P(x))$
Entropy
- 불확실성의 정도
- 불순도
- Entropy가 낮으면 분류 정확도가 높아짐
- 확률 변수의 평균 정보량(기댓값, 확률의 평균)
\(\begin{align*} Entropy &= E(-log(P(x))) \\ &= -sum(p(x) * log(p(x))) \end{align*}\)
- 원래는 p(x)로 같은데, Cross Entropy Error에서는 $y$, $\hat{y}$을 사용하므로 Cross가 붙음
4. Confusion Matrix(혼돈 행렬)
분류 모델을 Validation 하는 방법
1) Binary Confusion Matrix
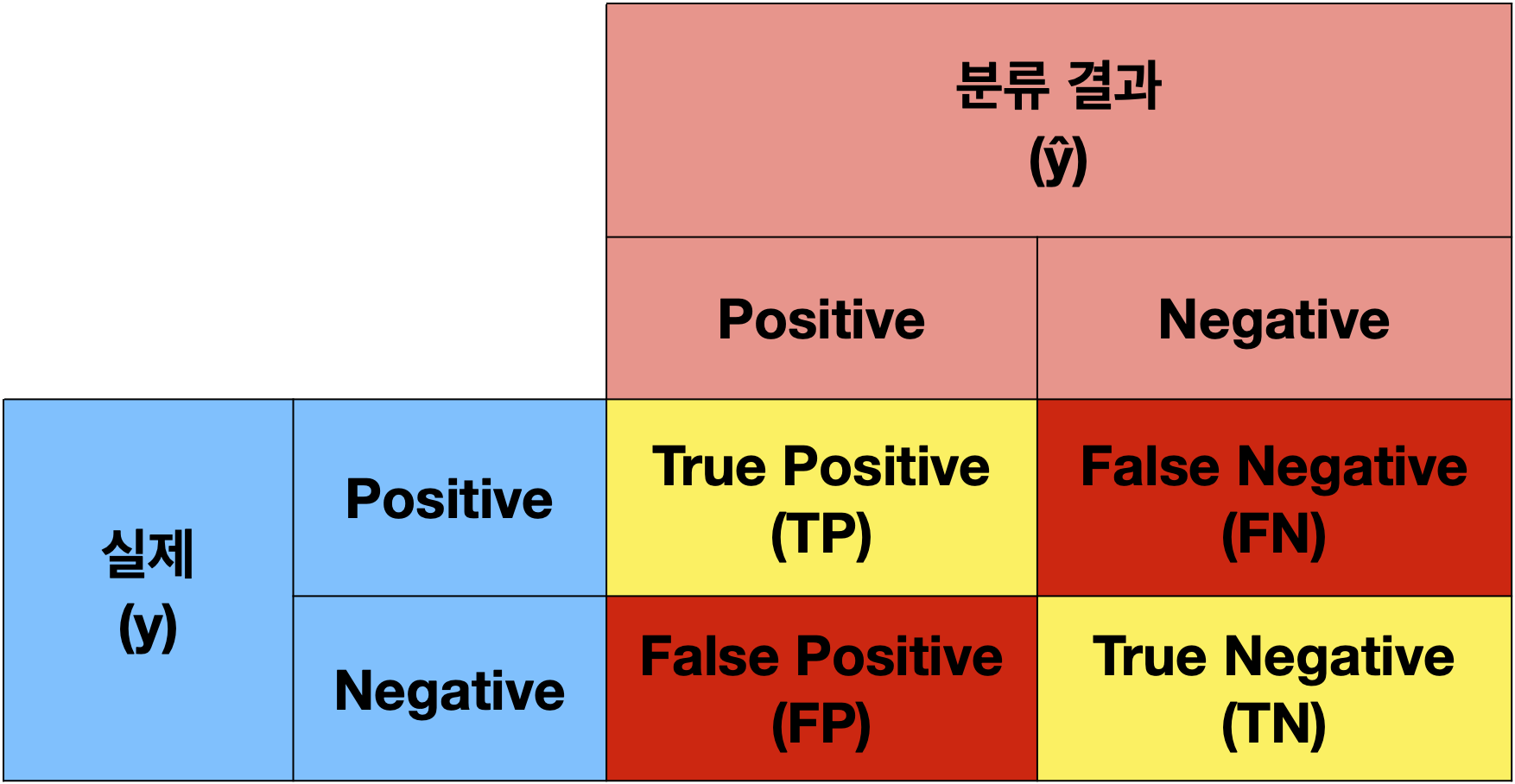
- Positive : 0
- Negative : 1
Business Impact
어떤 일에 대한 부정적인 영향
- Business Impact를 고려하여 모델을 평가해야함
- Positive
- 알고 싶은 데이터
- Positive 선택 시 Business Impact를 고려해야함
- 예
- 스팸 메일 필터링
- 스팸 메일을 확인하고 싶음 -> Spam(Positive)
- Spam 메일이 Ham 메일로 분류되는 것 보다, Ham 메일이 Spam 메일로 분류되면(Negative -> Positive) 중요 메일을 누락될 수 있으므로
Precision이 높은 모델을 만들어야 함
- 코로나 진단
- 코로나 양성을 확인하고 싶음 -> 양성(Positive)
- 음성이 양성으로 분류되는 것 보다, 양성이 음성으로 분류되면(Positive -> Negative) 감염병 전파의 위험이 크므로
Recall이 높은 모델을 만들어야 함
- 스팸 메일 필터링
- Positive
2) Accuracy(정확도)
Positive와 Negative로 맞게 분류된 데이터의 비율
$Accuracy = \cfrac{TP + TN}{TP + TN + FP + FN}$
3) Precision(정밀도)
Positive로 분류된 결과 중 실제 Positive의 비율
Negative를 Positive로 틀리게 분류 시 문제가 발생함
$Precision = \cfrac{TP}{TP + FP}$
4) Recall(재현율)
실제 Positive 중에서 Positive로 분류된 비율
Positive를 Negative로 틀리게 분류 시 문제가 발생함
$Recall = \cfrac{TP}{TP + FN}$
5) F1-Score
Precision과 Recall의 조화 평균
Precision과 Recall은 Trade-off 관계
$F1-Score = \cfrac{2}{\cfrac{1}{Precision} + \cfrac{1}{Recall}} = 2 \times \cfrac{Precision \times Recall}{Precision + Recall}$
Leave a comment