
[Machine Learning] 군집 분석(Cluster Analysis)
상대적으로 비지도학습보다는 지도학습이 실제로 더 많이 사용된다고 한다.
심층적인 내용은 생략하고, 간단하게 의미만 설명할 예정이다.
K-means Clustering은 다른 페이지에서 설명했다.
군집 분석(Cluster Analysis)
비지도학습에서 데이터의 유사성을 확인하기 위해 사용되는 분석 방법
군집 내 유사성, 군집 간 상이을 확인하는 분석방법
1. Mean Shift(평균 이동)
데이터 분포의 Peak(데이터가 가장 밀집된 곳)을 이동하며 분포의 중심을 찾는 알고리즘
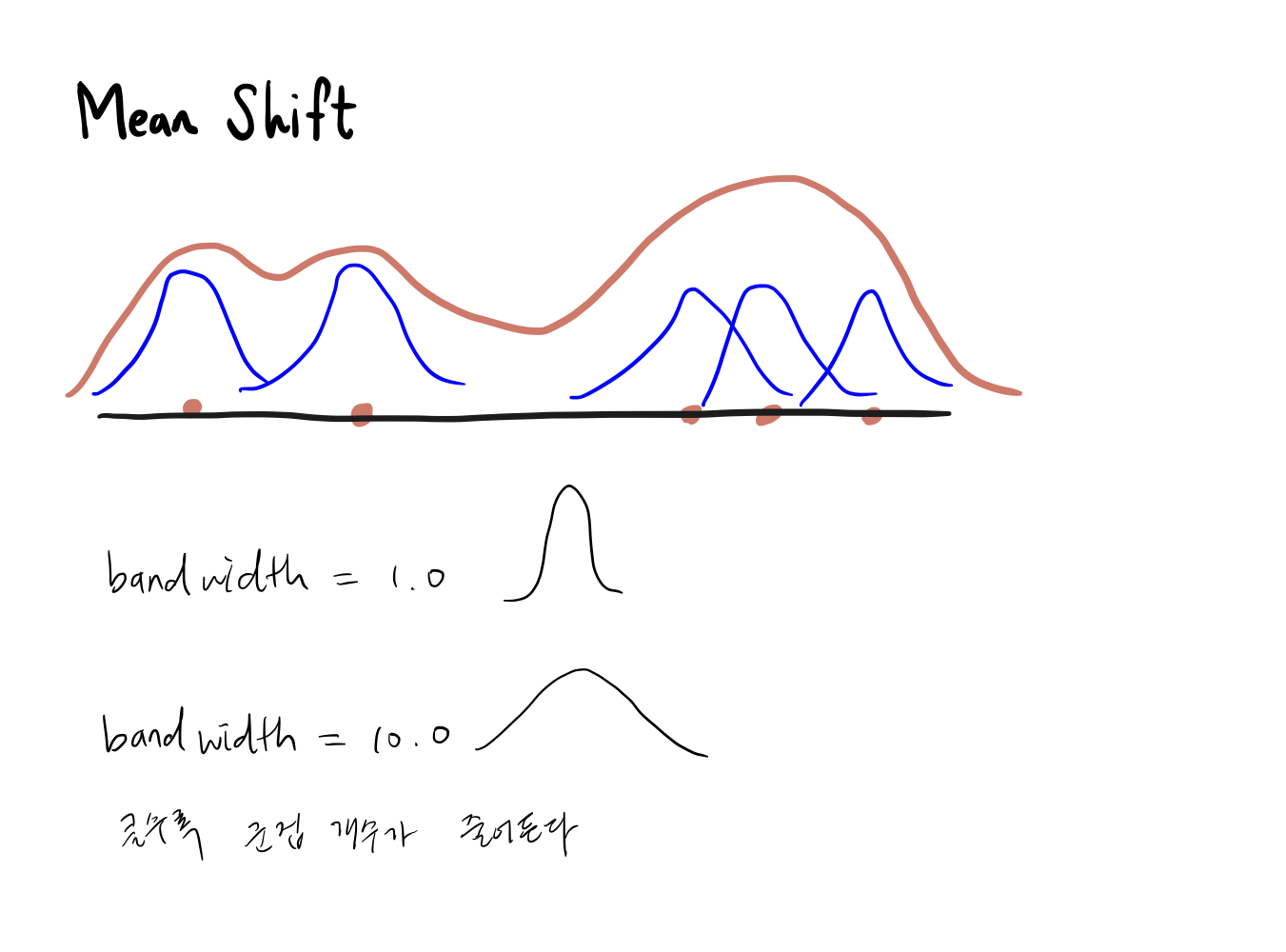
- 데이터의 분포를 이동하여 군집의 중심을 탐색
- 데이터 밀도가 가장 높은 곳으로 중심을 지속적으로 이동
- 군집의 중심점은 data points가 모여있는 곳이라는 가정
- 확률 밀도 함수(Probability Density Function)
- KDE(Kernel Density Estimation)
- Hyperparameter
- bandwidth(폭)
- bandwidth가 클수록 군집의 개수가 줄어든다.
- estimate_bandwidth를 사용해 권장되는 폭을 알 수 있다.
2. DBSCAN(Density-Based Spatial Clustering of Applications with Noise, 밀도 기반 클러스터링)
점들이 밀집된 곳을 하나의 군집으로 보고, 밀도가 높은 곳의 데이터끼리 군집으로 묶어나가는 알고리즘
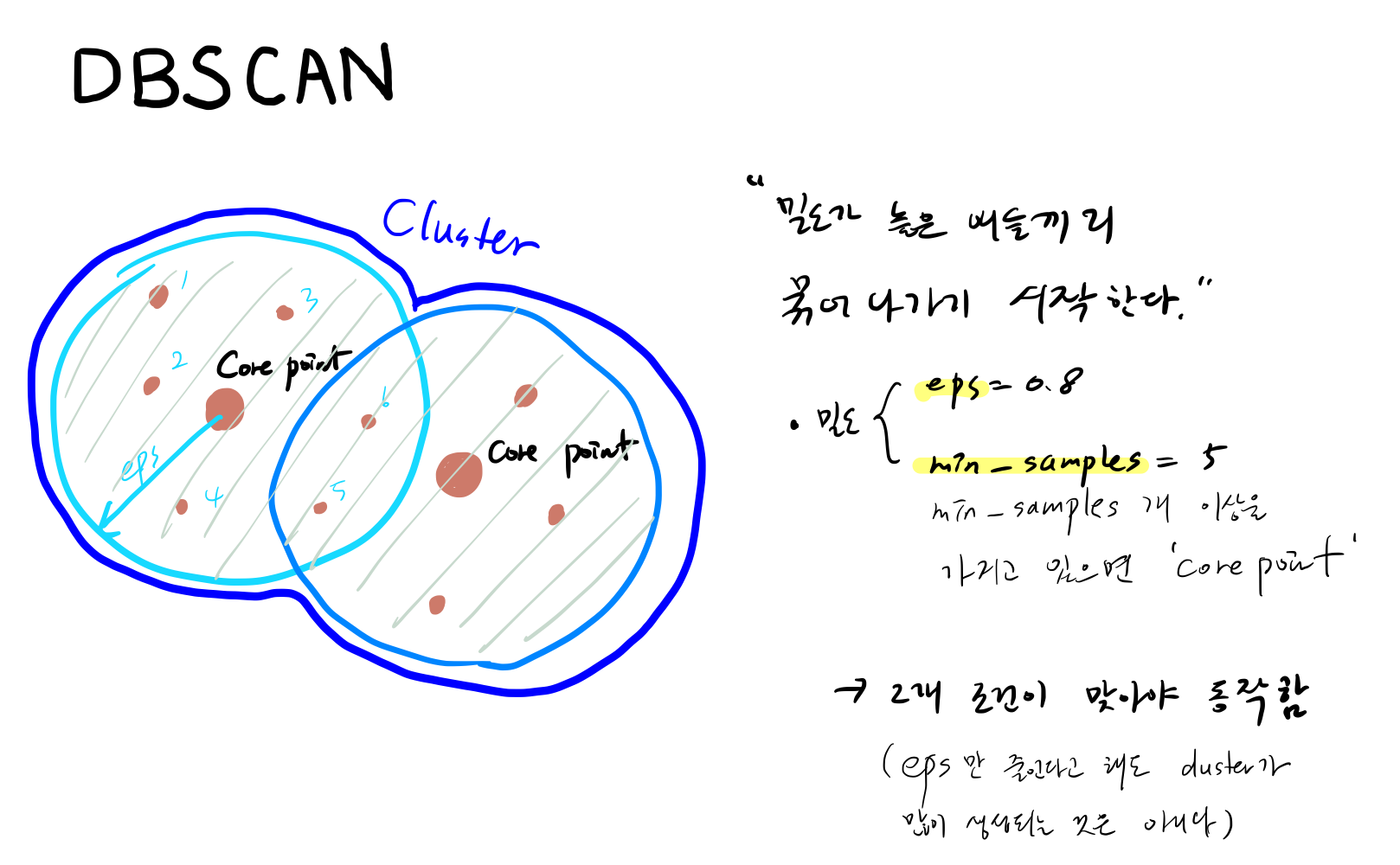
- 밀도(Density) 기반 군집
- 기하학적으로 복잡한 데이터에도 효과적으로 군집 가능
- 핵심 포인트(Core Point)들을 서로 연결하면서 군집화
- Hyperparameter
- epsilon(esp, 입실론 주변 영역)
- 개별 data points를 중심으로 ‘입실론 반경’을 가지는 주변 영역
- ‘Core Point’ 기준
- min point(min_samples, 최소 데이터 개수)
- 개별 data points의 ‘입실론 주변 영역’에 포함되는 다른 data points의 개수
- 조건 만족 시 ‘Core Point’로 지정
- epsilon(esp, 입실론 주변 영역)
3. GMM(Gaussian Mixture Model, 가우시안 혼합 모델)
Gaussian 분포가 여러개 혼합된 Clustering 알고리즘

- 데이터가 여러 개의 가우시안 분포(Gaussian Distribution)를 가진 데이터들의 집합이라고 가정
- 개별 정규분포의 모수(평균, 분산) 추정
- 각 data points가 어떤 정규분포에 해당하는지 확률 추정
- EM(Expectation and Maximization)
Leave a comment