
[Machine Learning] 회귀 분석(Regression Analysis)
Regression Analysis(회귀 분석)
과거의 결과값을 기준으로 미래의 결과값(수치)을 예측하는 방법(Model)
- 미래에 발생할 결과값이 과거의 평균으로 돌아간다(회귀)는 의미
- 회귀 모델($\hat{y} = wx+b$)을 사용하여 w와 b의 값을 추정
- 지도 학습의 일종
- 변수
- $x$ 값에 따라 $y$ 값이 결정됨
- 독립변수, 설명변수 : $x$
- 종속변수, 반응변수 : $y$
1. 회귀 분석의 종류
1) 단일 회귀 분석
Output($y$)에 영향을 주는 Input($x$)이 1개인 경우
- $y = wx + b$
- $y = w_1 x^2 + w_1 x + b$ (다항 회귀 분석)
2) 다중 회귀 분석
Input($x$)이 여러 개인 경우($y$는 1개)
- $y = w_1 x_1 + w_2 + x_2 + b$
3) 로지스틱 회귀 분석
확률값을 계산하여 분류
2. 회귀 분석 평가 지표
1) 상관계수(Correlation Coefficient)
$x$와 $y$의 관계를 확인하는 지표
$x_1$과 $x_2$의 관계를 확인하는 지표(다중회귀분석)
$-1 \le r \le 1$
- $-1$ : 음의 상관 관계
- $0$ : 상관 관계 없음
- $1$ : 양의 상관 관계
2) 결정계수(Coefficient of determination)
MSE와 함께 예측 모델의 평가 지표
“자동차의 무게와 연비의 관계에서, 무게로 연비를 설명할 수 있는가?”
$R$ = $R^2$ = $R\ squared$
$ 0 \le R^2 \le 1 $
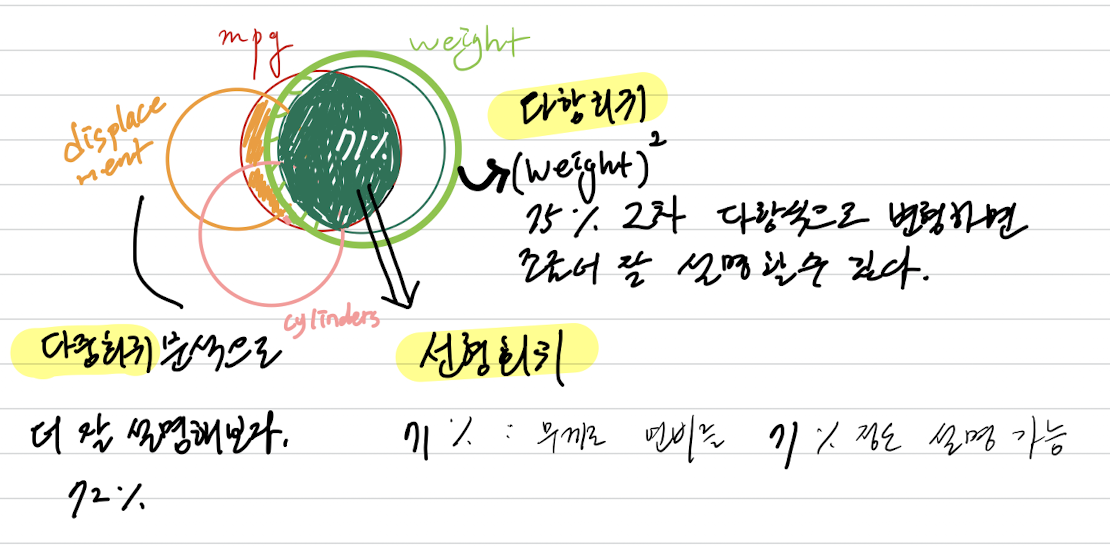
- 다중 회귀 분석이 마냥 좋은 것은 아니다. 설명하는 부분이 같거나 중복되는 경우(이미 설명한 부분을 또 설명하는 꼴) 다중회귀분석 결과가 낮을 수도 있다.
3. Scaling
변수(Feature, 특성)의 범위 조정
- 연속형 변수가 다양한 범위로 존재할 때 제곱 오차 계산 시 왜곡이 발생함
- 범위가 더 큰 변수에 맞추어서 가중치를 최적화(학습)하는 문제가 발생함
- 범위(Scale)가 다른 변수들의 범위를 비슷하게 맞추어야 편향과 계산량을 줄일 수 있음
- 정규화, 표준화 2가지 방법이 있음
- 정규화를 하나 표준화를 하나(Scale이 변해도) 데이터의 분포를 따라감
1) 정규화(Normalization)
변수의 스케일을 0 ~ 1 사이 범위로 맞추는 것(Min-Max Scaling)
- 변수의 범위가 정해진 값이 필요할 때 유용하게 사용됨
$X\ Normalization = \cfrac{X-min(X)}{max(X)-min(X)}$
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_Norm = scaler.fit_transform(X)
유의 사항
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# X에 관해서만 정규화를 진행한다.
# train data를 fit 시켜서 train date의 최댓값, 최솟값으로 train, test 데이터를 정규화 한다.
2) 표준화(Standardization)
변수의 평균을 0, 표준편차를 1로 만들어 표준정규분포의 특징을 갖도록 함
- 가중치(weight) 학습을 더 쉽게 할 수 있도록 함
$X\ Standardization = \cfrac{X-mean(X)}{std(X)}$
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_Stan = scaler.fit_transform(X)
4. Encoding(인코딩)
sklearn에서 ‘문자’를 분석할 수 없기 때문에 ‘숫자’ 형태로 변경하기 위해 인코딩을 진행함
1) Integer Encoding 문자형 변수를 숫자형 변수로 변경하여 변수 연산 범위 확대
-
from sklearn.preprocessing import LabelEncoder -
예
- europe -> 0
- korea -> 1
- usa -> 2
2) One-Hot Encoding
하나의 값은 True(1)이고, 나머지 값은 False(0)인 인코딩
-
from sklearn.preprocessing import OneHotEncoder -
예
- europe -> [1, 0, 0]
- korea -> [0, 1, 0]
- usa -> [0, 0, 1]
Leave a comment