
[Deep Learning] 임베딩(Embedding)
1. 임베딩(Embedding)
단어를 벡터로 표현하는 방법
자연어를 컴퓨터가 이해하고 처리하게 하기 위해서는
컴퓨터가 이해할 수 있도록 자연어를 벡터로 변환해야한다.
단어나 문장을 벡터로 변환하고 벡터 공간으로 ‘끼워 넣는’ 의미로 생각하면 된다.
또한, 변환하는 방법에 따라 처리 성능이 달라진다.
자연어가 아닌 문제에서는 보통 원-핫 인코딩을 사용하여 문자를 벡터로 변환한다.
하지만, 자연어에서 문장은 수많은 단어로 구성되어 있기 때문에
구성하는 단어의 개수가 늘어나게 되면 단어 집합의 크기만큼 벡터에 ‘0’ 값이 한없이 늘어나게 된다.
행렬의 값이 대부분 0으로 표현되는 것을 희소 표현(Sparse Representation)이라고 한다.
희소 표현 방식은 공간적 낭비를 일으키고, 단어의 의미를 포함하기 어렵다는 문제가 있다.
회소 표현의 예
강아지 = [ 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, …, 0]
임베딩은 밀집 표현(Dense Representation)으로 단어를 변환하는데
밀집 표현은 지정된 차원 안에 실수값을 사용하여 조밀하게 표현하는 방법이다.
밀집 표현의 예
강아지 = [0.2, 0.3, 0.5, 0.7, 0.2, …, 0.2]
2. 임베딩의 종류
임베딩의 종류는 여러가지가 있으나 Word2Vec, Glove가 가장 많이 사용되고 있다.
1) 워드 투 벡터(Word2Vec)
문장 내 비슷한 위치(Neighbor words)에 있는 단어로부터 유사도를 획득하는 방법
- 원-핫 인코딩 및 이전 Similiarity 방식의 단점을 보완한 방법
- 각각의 단어 벡터가 단어 간 유사도를 반영한 값을 가지고 있음
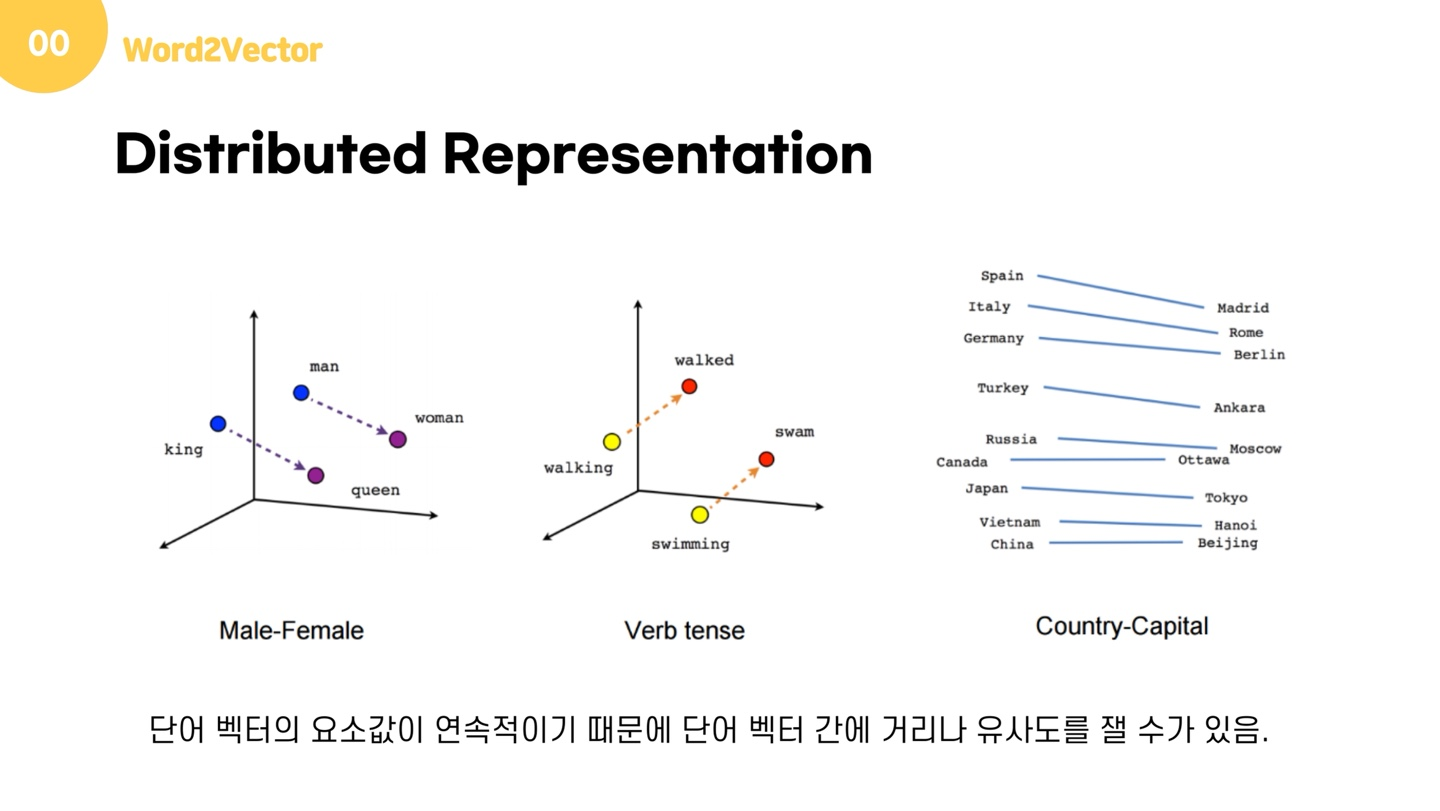
분산 표현
- “비슷한 위치에서 등장하는 단어는 서로 비슷한 의미를 가진다.” 라는 분포 가설의 가정 하에 문자를 표현하는 방법
- 분포 가설을 이용하여 단어의 셋을 학습하고, 벡터에 단어의 의미를 여러차원에 분산하여 표현한다.
Word2Vec의 학습 방식 두 가지
일반적으로 Skip-gram이 CBOW 보다 성능이 좋다고 한다.
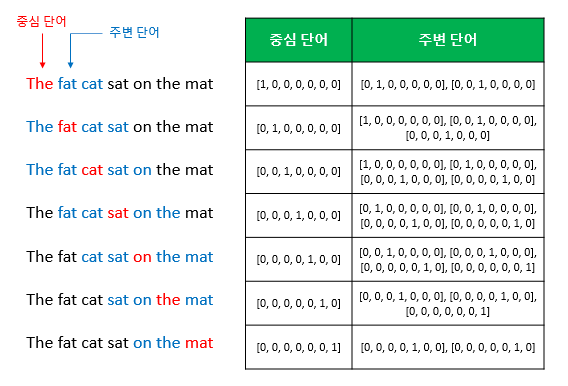
(1) CBOW
- 주변에 있는 단어를 사용하여 중간에 있는 단어를 예측하는 방법
- 윈도우를 이동(Sliding Window)하며 생성된 데이터로 학습
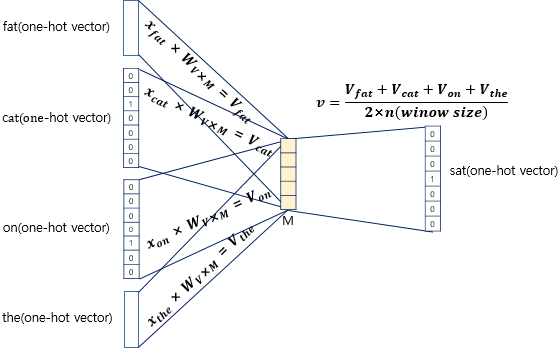
예를 들어 코퍼스가 아래와 같은 문장이 있고, 윈도우 크기가 2이며 ‘sat’을 예측한다고 하면
주변의 2개씩 총 4개의 벡터가 입력되고 ‘sat’을 예측하게 된다.
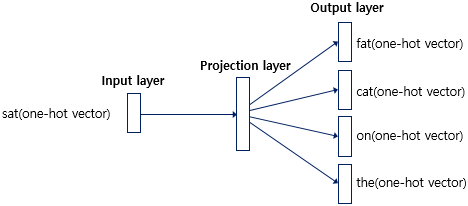
(2) Skip-gram
- 중간에 있는 단어를 사용하여 주변에 있는 단어를 예측하는 방법
- 윈도우 크기만큼 주변 단어를 사용하여 생성된 데이터로 학습
예를 들어 코퍼스가 아래와 같은 문장이 있고, 윈도우 크기가 2이며 ‘cat’으로부터 주변 2개 단어들을 예측한다고 하면
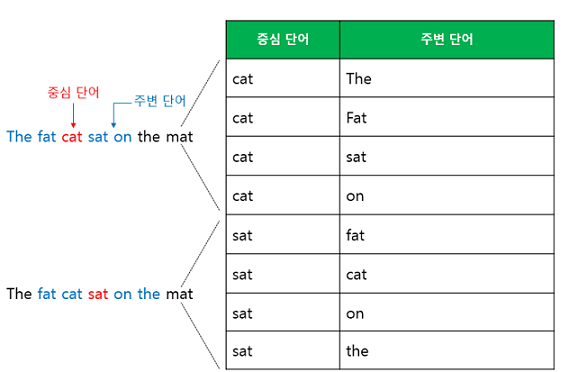
‘cat’이 입력되고 주변의 2개씩 총 4개의 단어를 예측하게 된다.
2) 글로브(GloVe)
카운트 기반(BoW, …)과 예측 기반(Word2Vec, …)을 모두 사용하는 방법론
- Word2Vec 만큼 뛰어난 성능을 보여주고 있다.
- 두 방법론을 비교하여 성능이 좋은 것을 사용할 것.
임베딩의 최근 동향
위키피디아 등 방대한 코퍼스로부터 Word2Vec, GloVe 등을 통해 사전 훈련된 임베딩 벡터를 불러오는 방법을 사용한다.
(1) BERT(Bidirectional Encoder Representations from Transformers)
구글이 공개한 사전 훈련된 모델
(2) GPT(Generative Pre-Training)
OPENAI가 공개한 사전 훈련된 모델
References
- https://wikidocs.net/
- https://velog.io/@numver_se/Word2vec논문정리
Leave a comment