
[Deep Learning] 자연어 처리(NLP)
1. 자연어 처리(Natural Language Processing, NLP)
학습된 모델로 번역, 문장 요약, 문장 생성 등의 언어와 관련된 작업을 수행하는 것
NLP는 이해 목적이 아니라, 연산(Computation)이나 처리(Processing)의 영역이다.
컴퓨터는 사람이 사용하는 언어를 이해할 수 없다…
NLP는 자연어 연구를 위해 특정 목적을 가지고 수집한 언어의 표본인 말뭉치(Corpus)를 모델 학습에 활용한다.
수학적 연산을 위해 ‘텍스트’를 숫자로 변환하는 작업(Cleansing)이 필요한데,
컴퓨터가 연산할 수 있는 형태인 벡터로 변환한다.
2. 전처리(Preprocessing)
자연어 학습에 적합하도록 수집된 텍스트를 사전 처리하는 작업
1) 토큰화(Tokenization)
수집된 말뭉치를 토큰(Token) 단위로 나누는 작업
토큰의 단위는 일반적으로 의미를 가지는 단위로 정의하고,
일반적으로 형태소(Morpheme) 단위의 토큰화가 수행된다.
토큰의 단위
- 문장(Sentence), 단어(Word), 문자(Character) 형태
- 불용어(Stop Words)
- 어간 추출(Stemming) = 형태소 분석
- 표제어 추출(Lemmatization)
2) 인코딩(Encoding)
말뭉치를 숫자로 바꾸는 작업
- 정수 인코딩(Integer Encoding) : 단어를 정수에 매핑하는 방식
- 원-핫 인코딩(One-Hot Encoding) : 단어를 벡터의 차원으로 0과 1을 사용하여 표현하는 방식
3. 단어를 표현하는 방법들
인코딩 이외에 말뭉치를 숫자로 표현하는 방법들
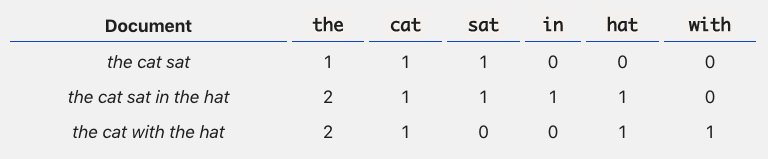
1) Bow(Bag of Words)
문서가 가지는 모든 단어를 문맥과 순서를 무시하고,
일괄적으로 문장에 포함된 단어에 대해 빈도값을 부여해 특징을 추출하는 방법
M개의 문서(문장)과 N 종류의 단어로 행렬(Term(Word)-Document Matrix)를 생성한다.
행렬은 희소 행렬 형태이고, 행렬 내 값은 빈도수를 의미한다.
발생 빈도가 높을수록 중요한 단어로 인식한다.
장단점
- 장점
- 쉽고 빠른 구축
- 예상보다 문서의 특징을 잘 반영함
- 단점
- 자주 등장하는 단어에 높은 중요도를 부여하는데 나타나는 부작용 발생
- 단어의 순서를 고려하지 않아 문맥 의미(Semantic Context) 반영이 부족함
- 대부분 ‘0’으로 구성된 희소 행렬(Sparse Matrix)을 생성하여 학습시간이 증가하고, 성능에 부정적인 영향을 줌
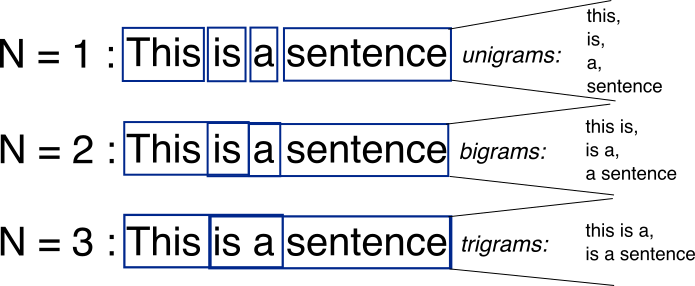
2) n-gram
가지고 있는 말뭉치에서 n개의 단어 뭉치로 끊어 하나의 토큰으로 간주하는 방법
BoW의 단어 순서를 무시하는 단점을 보완한 모델이며,
가지고 있는 말뭉치를 몇개의 단어로 나누느냐에 따라 n 이 달라진다.
3) TF-IDF(Term Frequency - Inverse Document frequency)
단어의 빈도와, 문서(문장)의 빈도를 사용하여 각 단어마다 중요한 정도를 가중치로 주는 방법
단어의 빈도수만 고려하는 BoW의 단점을 보완한 모델이며,
문서의 유사도를 구하는 작업, 검색 결과의 중요도를 정하는 작업, 문서 내 단어의 중요도를 구하는 작업에 쓰일 수 있다.
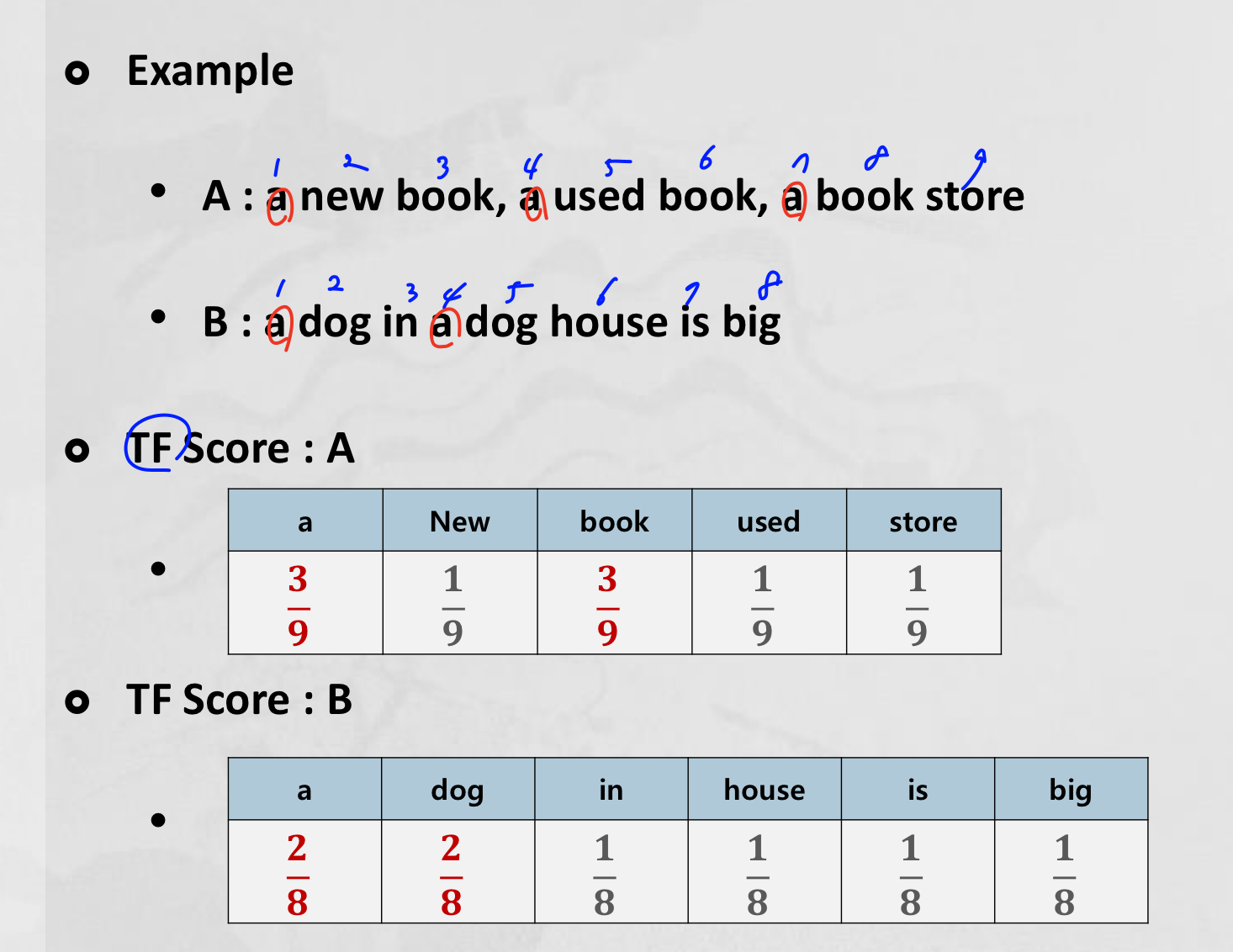
(1) TF Score
특정 문서(문장)에 등장한 특정 단어의 등장 횟수
개별 문서(문장)에 자주 나타나는 단어에 높은 가중치를 부여하기 위해 계산한다.
(2) IDF Score
특정 단어가 등장한 문서(문장)의 수
모든 문서(문장)에서 전반적으로 자주 나타나는 단어에는 패널티를 부여하기 위해 계산한다.
(3) TF-IDF Score
$TF-IDF(T) = TF(T) \times log\Big(\cfrac{M}{IDF(T)}\Big)$

4. 유사도(Similarity)
단어나 문장을 벡터로 변환한 후 유사도를 비교하는 것
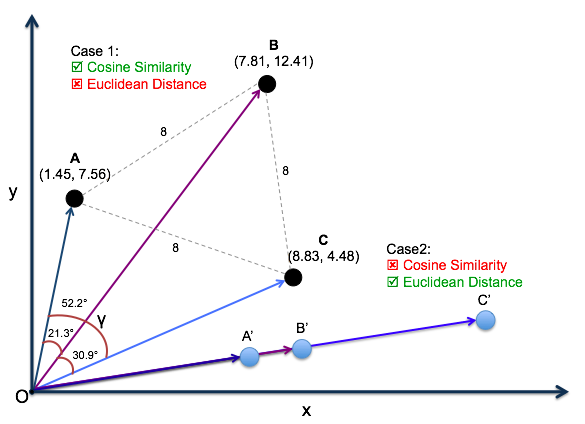
1) 유클리디안 거리(Euclidean Distance Similarity)
벡터 간 거리를 계산하여 유사도를 측정
- n차원 공간에서 점 p, q에 대한 유클리디안 거리 : $\sqrt{\sum\limits_{i=1}^n (p_i-q_i)^2}$
- 거리가 짧을수록 유사도가 높음
2) 코사인 유사도(Cosine Similarity)
벡터간 사잇각을 계산하여 유사도를 측정
$ similarity = cos(\theta) = \cfrac{A \cdot B}{\lVert A \rVert \lVert B \rVert} = \cfrac{\sum\limits_{i=1}^n A_i \times B_i}{\sqrt{\sum\limits_{i=1}^n (A_i)^2} \times \sqrt{\sum\limits_{i=1}^n (B_i)^2}}$
- 사잇각이 작을수록 유사도가 높음
- 벡터의 크기가 아닌 방향성 기반
References
- https://towardsdatascience.com/a-simple-explanation-of-the-bag-of-words-model-b88fc4f4971
- https://deepai.org/machine-learning-glossary-and-terms/n-gram
- https://medium.com/@sasi24/cosine-similarity-vs-euclidean-distance-e5d9a9375fc8
Leave a comment