
[Deep Learning] 텐서플로(TensorFlow) & 케라스(Keras)
1. 텐서플로(TensorFlow) & 케라스(Keras)
1) 텐서플로(TensorFlow)
기계 학습을 위한 오픈소스 라이브러리
- 신경망 같은 머신러닝 프로그램에 활용되는 머신러닝 프레임워크
- 구글 브레인 팀에 의해 개발됨
- 딥러닝에서 훈련 및 추론에 주로 사용됨
- 현재 딥러닝 프레임워크 중 Keras와 같이 가장 많이 사용되고 있음
- 빠르게 프로토타입을 제작하고 디버깅을 구현할 수 있음
- 플랫폼에 관계없이 모델을 학습시키고 배포할 수 있음
- 코드 수정 없이 CPU/GPU 모드로 동작이 가능함
- Keras API를 할용하여 손쉽게 모델을 빌드할 수 있음
2) 케라스(Keras)
Python 기반의 딥러닝 프레임워크
- 사용자 중심의 상위 레벨 인터페이스를 제공함
- 하위 레벨 계산은 TensorFlow 사용
- 사용자 친화적이고 직관적인 API를 통해 쉽게 딥러닝 모델을 생성할 수 있음
- 케라스 내부적으로는 TensorFlow, Theano, CNTK 등 딥러닝 전용 엔진이 구동됨
- 다중 입력 및 출력 구성이 가능함
- TensorFlow 1.14 버전부터 공식 Core API로 추가됨
3) 텐서플로와 케라스
- 텐서플로 : 기존 기능 외 새로운 방식을 이용하거나 구체적인 신경망 개발 시 사용
- 케라스 : 기존 기능만 사용하거나 비교적 단순한 신경망 개발 시 사용
2. 텐서(Tensor)
딥러닝 학습을 위한 기본 데이터 단위(숫자를 담기위한 구)
다차원 행렬
- 임의의 차원(Dimension) 또는 축(Rank)을 가짐
- Tensorflow에서 자료는 실수형(Float)만 입력 가능하다.
1) 텐서의 차
| Rank | Type | Example |
|---|---|---|
| 0 | Scalar | 0 |
| 1 | Vector | [0,1] |
| 2 | Matrix | [[0,1], [1,0]] |
| 3 | 3 Tensor(Array) | [[[0,1], [1,0]], [[1,1], [1,1]], [[2,2], [2,2]]] |
| N | N Tensor |
2) 자연어 처리(Natural Language Processing)에서의 텐서
문장과 단어를 숫자 벡터로 매핑함
예시
하얀 고양이, 하얀 강아지, 하얀 비둘기
-
Unique Word Vector Dictionary(Rank 1)
Word Index One-Hot Encoding Vector 하얀 0 [1,0,0,0] 고양이 1 [0,1,0,0] 강아지 2 [0,0,1,0] 비둘기 3 [0,0,0,1] - Sentence(Rank 2)
- 하얀 고양이 : [[1,0,0,0], [0,1,0,0]]
- 하얀 강아지 : [[1,0,0,0], [0,0,1,0]]
- 하얀 비들기 : [[1,0,0,0], [0,0,0,1]]
- mini-batch Input(Rank 3)
- 하얀 고양이 하얀 강아지 하얀 비둘기
- [[[1,0,0,0], [0,1,0,0]], [[1,0,0,0], [0,0,1,0]], [[1,0,0,0], [0,0,0,1]]]
- (3, 2, 4) : (Sample Dimension, Length of Sentence, Word Vector Dimension)
- 하얀 고양이 하얀 강아지 하얀 비둘기
3) 이미지 처리에서의 텐서
(1) Grayscale(Rank 3)

- (3, 5, 5) : (Number of Images, Rows, Columns)
(2) RGB color(Rank 4)
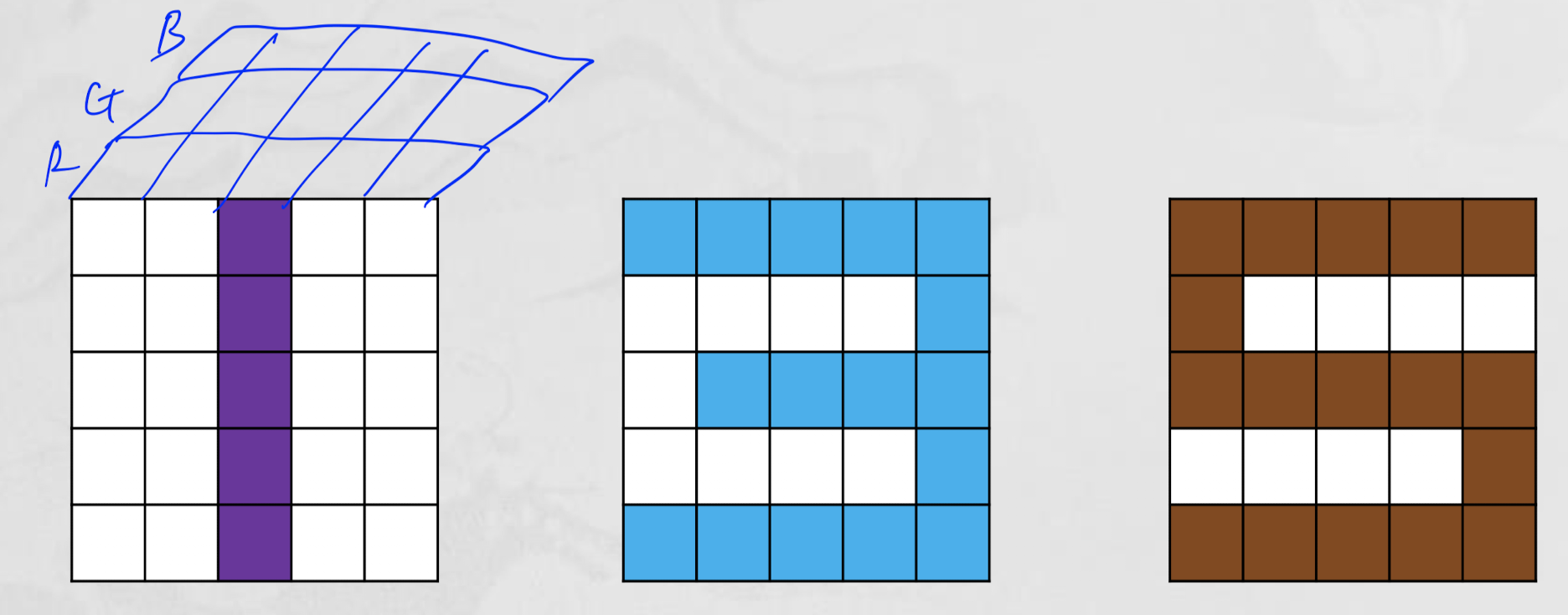
- (3, 5, 5, 3) : (Number of Images, Rows, Columns, RGB Channel)
(3) Video(Rank 5)

- (3, 5, 600, 800, 3) : (Video Frames, Number of Images, Rows, Columns, RGB Channel)
3. 케라스 모델링 순서
아래 순서대로 모델링을 진행하며, 목표를 달성할 때까지 모델 구조 및 Hyparameter를 변경함
*) Data Collection
*) Data Preprocessing & EDA
- Input data ‘Float’ Type Casting 처리
- Classification의 경우 Target Encoding
- Normalization or Standardization
1) Define
모델의 모양(신경망 구조) 정의
- Sequential Model
- Layers / Units(Node) : Hidden Layer, Node 개수
- Input Shape : Input Tensor의 차원
- Activations : Sigmoid, ReLU, …
2) Compile
모델 학습 방법 설정
- Loss : 예측(MSE), 분류(Binary CEE, Categorical CEE)
- Optimizer : Adam, RMSProp, …
- Metrics : Accuracy, Recall, …
3) Fit
모델 학습 수행
- Train Data : 학습에 사용되는 데이터
- Epochs : 반복 횟수
- Batch Size : mini-batch의 크기(배치마다 가중치 업데이트)
- Validation Data
4) Evaluate
모델 성능 평가
- Test Data
- Evaluate
- Plot
5) Predict
실제 환경에 모델 적용(모델 배포)
- Test Data
- Probability
- Classes
Leave a comment