
[Deep Learning] 경사 하강법 최적화 알고리즘(Optimization Method)
경사 하강법 최적화 알고리즘(Gradient Descent Optimization Method)
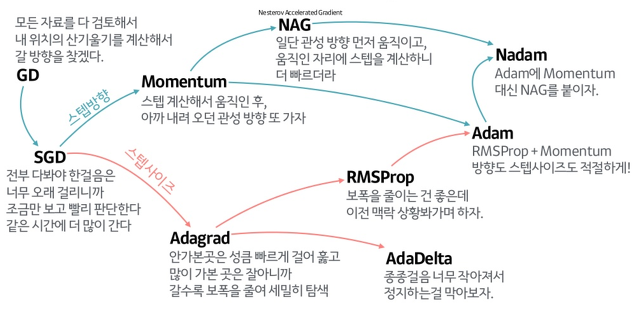
다양한 형태의 경사하강법
1. 경사 하강법 최적화 알고리즘의 종류
1) 확률적 경사 하강법(Stochastic Gradient Descen, SGD)
2) 모멘텀(Momentum)
3) Nesterov Momentum
4) 아다그라드(Adaptive Gradient, Adagrad)
5) Root Mean Square Propagation(RMSProp)
6) 아담(Adaptive Moment Estimation, Adam)
7) AdaDelta
…
 https://seamless.tistory.com/38
https://seamless.tistory.com/38
2. 확률적 경사 하강법(Stochastic Gradient Descen, SGD)
전체 데이터(batch) 대신 일부 데이터(mini-batch)를 사용하는 경사 하강법
$w_{t+1} = w_t - \gamma \cdot dE$
- batch GD 보다 부정확할 수 있지만, 계산 속도가 훨씬 빠름
- 같은 시간에 더 많은 step을 이동할 수 있음
- 일반적으로 batch 결과에 수렴함
- 현재 다양한 SGD의 변형이 존재함
3. 모멘텀(Momentum)
이동 과정에서 ‘관성’을 반영하는 경사 하강법
$w_{t+1} = w_t - \gamma \cdot dE + \mu \cdot dw_{t-1}$
$dw_{t-1} = w_t -w_{t-1}$
- 과거에 이동한 방향을 기억하여 다음 이동에 반영함
- 이전 가중치의 업데이트 양과 방향이 크게 변화하지 않도록 조정(이전 방향에서 크게 벗어나지 않도록)
- 바로 직전 시점의 가중치 업데이트 변화량을 적용함
4. 아다그라드(Adaptive Gradient, Adagrad)
학습 횟수가 증가함에 따라 학습률을 조절하는 경사 하강법
$w_{t+1} = w_t - \cfrac{\gamma}{\sqrt{g}} \cdot dE$
학습률 감쇠식(학습 계수 감쇠율 : $\rho$, 학습횟수 : $n$
$\gamma = \cfrac{\gamma}{(1+\rho \cdot n)}$
$ g = g + (dE)^2$
- 학습률이 작으면 안정적이지만, 학습 속도가 느려짐
5. Root Mean Square Propagation(RMSProp)
Adagrad의 단점인 gradient 제곱합을 지수 평균으로 대체한 경사 하강법
6. 아담(Adaptive Moment Estimation, Adam)
RMSProp과 Momentum 방식의 장점을 합친 경사 하강법
- Momentum과 같이 지금까지 계산해온 기울기의 지수 평균을 저장함
- RMSProp과 같이 기울기 제곱 값의 지수 평균을 저장함
Leave a comment