
[Fluent-bit] Fluent-bit 개요
1. Fluent-bit ?
https://docs.fluentbit.io/manual/
Fluent-bit은 Fluentd 보다 경량화된 로그 프로세싱 오픈소스 툴이다.
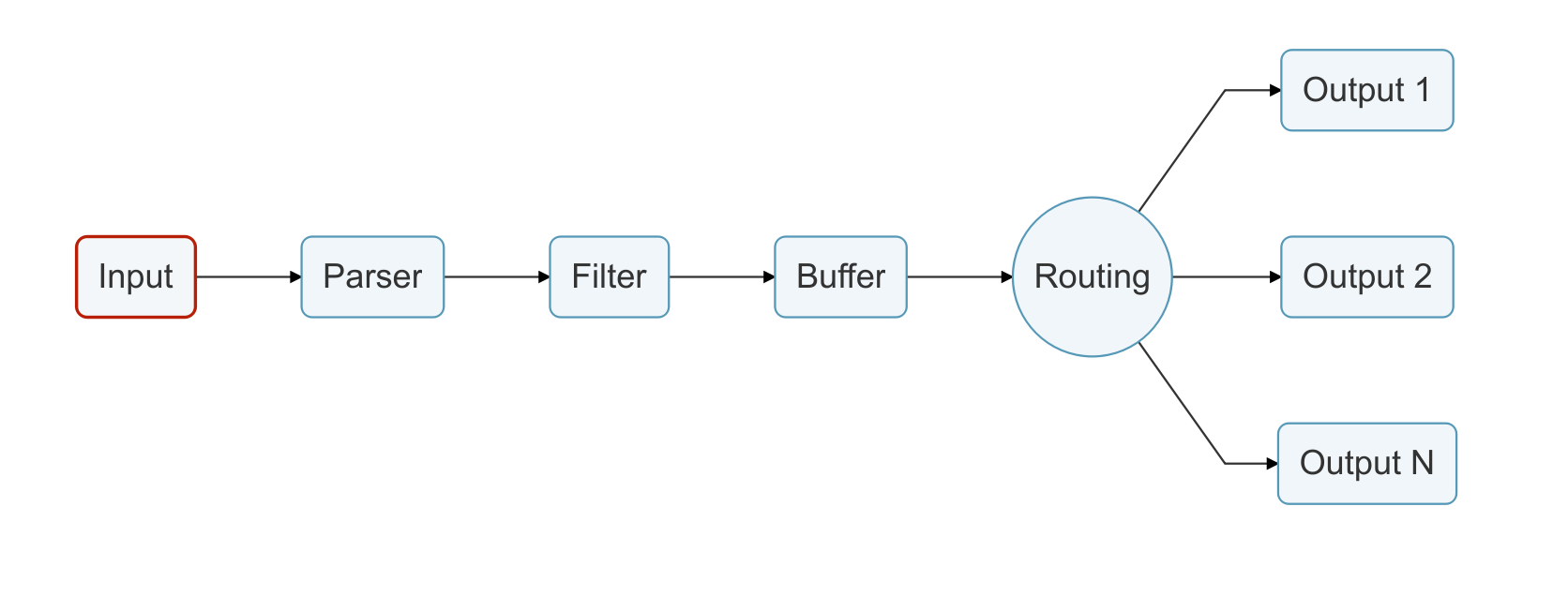
- Input : 특정 로그가 생성될 때마다 읽어 들인다(수집).
- Parser : 수집된 로그를 원하는 형식(정규식)에 맞게 필드/값 형태로 변환한다.
- Filter : 파싱된 로그를 요구사항에 맞게 필드 또는 값을 처리(추가/수정/삭제)한다.
- Buffer : 처리된 로그를 어디론가 보내기 위해 버퍼에 담는다(filesystem 또는 Memory)
- Output : 버퍼에 있는 로그를 어디론가 보낸다(ElasticSearch 또는 S3).
2. Story
Why
Fluent-bit을 사용하게된 계기는 Agent가 가볍고, Fluentd보다 사용하기에 단순해서다.
성능은 떨어지겠지만 가벼운 버전으로 초기에 셋업하는 용도로 사용하고, 성능 상 문제가 될 경우 Fluentd로 변경하려 했다.
웬걸, 생각보다 잘 동작해서 끝까지 살아 남았고 상용에 배포되기까지 했다.
How
약 1년 동안 Fluent-bit을 통해 Nginx, EKS container 로그를 AWS OpenSearch(ElasticSearch), AWS S3로 적재했다.
Fluent-*으로 Pipeline을 구축하고 ElasticSearch에 저장 한 후에 Kibana로 시각화했다(EFK).
Kibana로 대시보드를 구축하고, 상용 배포 시 현재 Traffic은 어떻고 배포 중에 Error가 발생하는 지 모니터링하는 데 활용했다.
Error가 발생되면, 의사결정에 따라 배포를 유보하거나 중단하여 End User에게 최소한의 피해가 가게끔 했다.
Performance
약 3000 TPS(초당 약 3천 건의 로그가 쌓이는 환경)를 큰 문제 없이 적재했고, 로그 보관 비용 이외에 별도 비용은 들지 않았다.
Filter - Rewrite Tag, Filesystem을 사용한 Buffering, Out Of Memory 등 몇 가지 이슈가 있었다.
“이런 기능이 있었으면 좋겠는 데?” 하는 기능은 웬만큼 다 있다.
Fluentd와 달리 참고할 문서가 많지 않았고, 한창 개발 중인 Open Source다 보니 해결되지 않은 오류가 많았다. 공식 Repository에 가보니 수많은 개발자들이 아우성하고 있었다.
또, Documentation이 불친절하여 이것 저것 테스트하느라 많은 시행착오를 겪었다.
So What ?
Fluent-bit 사용 방법을 nginx, k8s로 분류하고, 기본/고급으로 나누어 포스팅 했다.
| nginx | k8s |
|---|---|
| 기본 | 기본 |
| 고급 | 고급 |
Leave a comment