
[Machine Learning] 규제화(Regularization)
Overfitting
모델이 Train 데이터에만 최적화된 상태
Loss가 Train Data에 대해서만 낮지만, Validation Data에 대해서는 높다.
Overfitting 발생 원인
1) Data point 개수가 적을 때
2) Model Capacity가 높을 때
- 파라미터($w_i$) 개수가 많은 경우
Regulation(규제화)
Model이 Train Data에 너무 학습되지 않도록 방해하는 것
Overfitting을 회피할 목적으로 파라미터 개수를 줄이는 방법
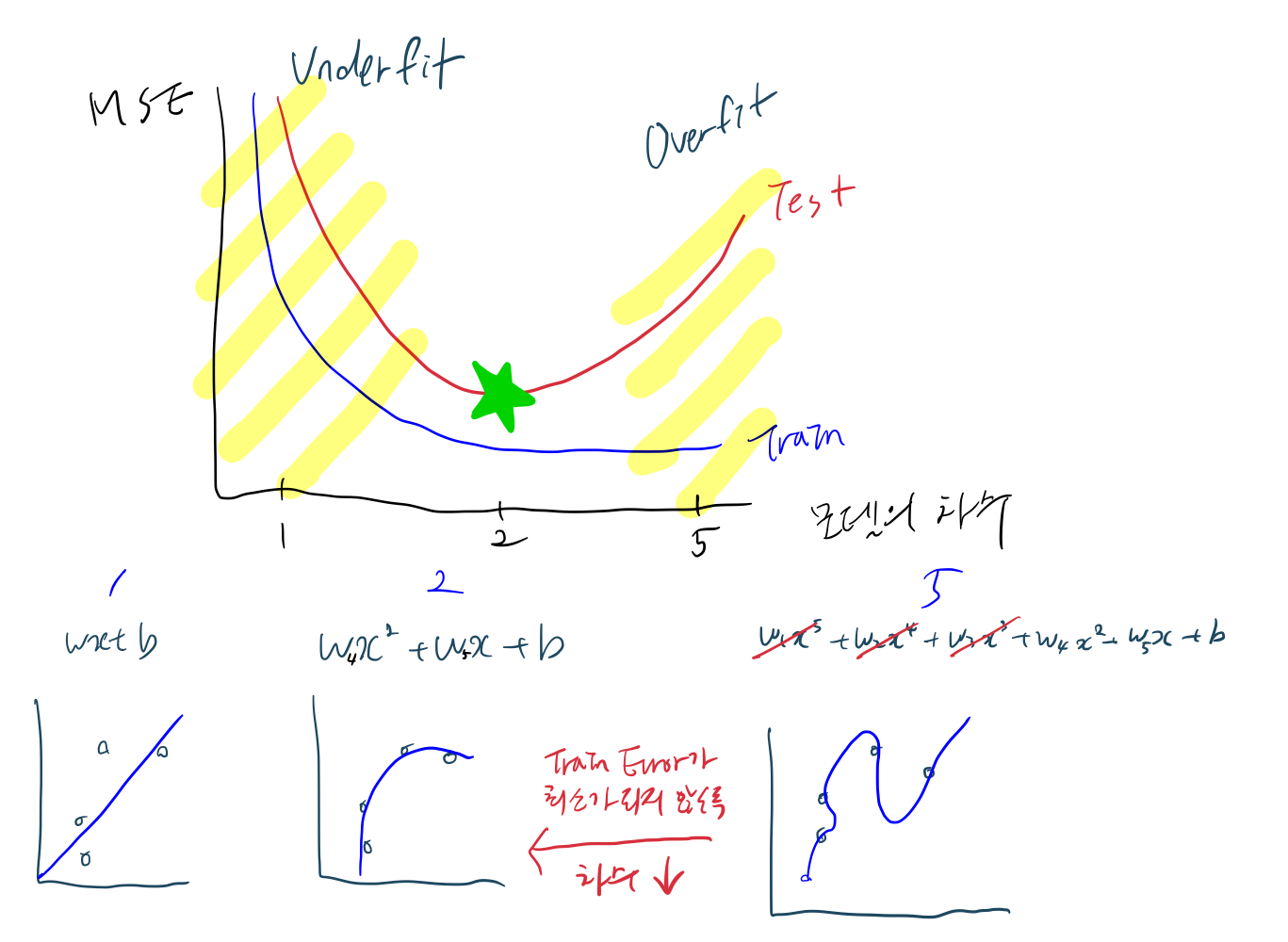
- w의 차수가 크면 비용 함수가 구불구불해지면서 모든 데이터에 맞게 되는 Overfitting이 일어난다.
- 이러한 성질을 최소화 하기 위해 특정 값을 더하는데, 무엇을 더하는지에 따라 모델이 달라진다.
- 특정 값을 더하면 지속적으로 노이즈가 발생하여 Loss 증가하게 만든다.
Ridge Regression(리지 회귀)
MSE 식에 $\alpha \sum\limits_{j=1}^m {w_j}^2$ 를 더하여 w를 제어한다.
규제 방식 : L2
- $\alpha = 1$(default)
- $\alpha$ 를 높이면 계수를 0에 더 가깝게 만들어 Train 모델의 성능은 나빠지지만 일반화에는 도움이 된다.
- $\alpha$ 를 낮추면 계수에 대한 제약이 풀리면서 과적합이 일어날 가능성이 증가한다.
- Test data에 대한 성능이 높아질 때까지 alpha 값을 줄이며 조절한다(Hyperparameter).
- 성능이 비슷하다면, 보통 Ridge와 Lasso 중 Ridge를 선호한다(어떤 계수도 0이 되지 않기 때문).
Lasso Regression
MSE 식에 $\alpha \sum\limits_{j=1}^m \left\vert w_j \right\vert$ 를 더하여 w를 제약한다.
규제 방식 : L1
- Ridge와 같이 계수를 0에 가깝게 만들려고 하는데, 방식이 조금 다르다.
- L1 규제 결과로 어떤 계수는 정말 0이 되는데, 모델에서 완전히 제외되는 Feature가 생긴다
(Feature selection이 자동으로 이루어진다고 볼 수 있음). - $\alpha = 1$(default)
- $\alpha$ 를 높이면 계수를 0에 더 가깝게 만들어 Train 모델의 성능은 나빠지지만 일반화에는 도움이 된다.
- $\alpha$ 를 낮추면 계수에 대한 제약이 풀리면서 과적합이 일어날 가능성이 증가한다.
- 예를 들어, 과소적합이 발생하여 $\alpha$ 를 줄일 때 max_iter(반복 실행하는 최대 횟수)의 기본값은 늘린다.
- Feature가 많고 그 일부만 중요하다면(0이 되는 경우 발생 고려) Lasso를 선호할 수 있다.
ElasticNet
Ridge와 Lasso를 결합한 회귀($l_1 \times \sum\limits_{j=1}^m \left\vert w_j \right\vert + \cfrac{1}{2} \times l_2 \times \sum\limits_{j=1}^m {w_j}^2$)
규제 방식 : L1 + L2
Leave a comment