
[Machine Learning] K-Nearest Neighbors(KNN)
K-Nearest Neighbors(KNN)
데이터 분류 시 이웃한 데이터 포인트의 분류를 바탕으로 하는 알고리즘
데이터의 Label을 정의할 때 주변 데이터들의 Label을 조사하여 다수결로 K개 이상이며, 가장 많은 것의 Label로 정의함
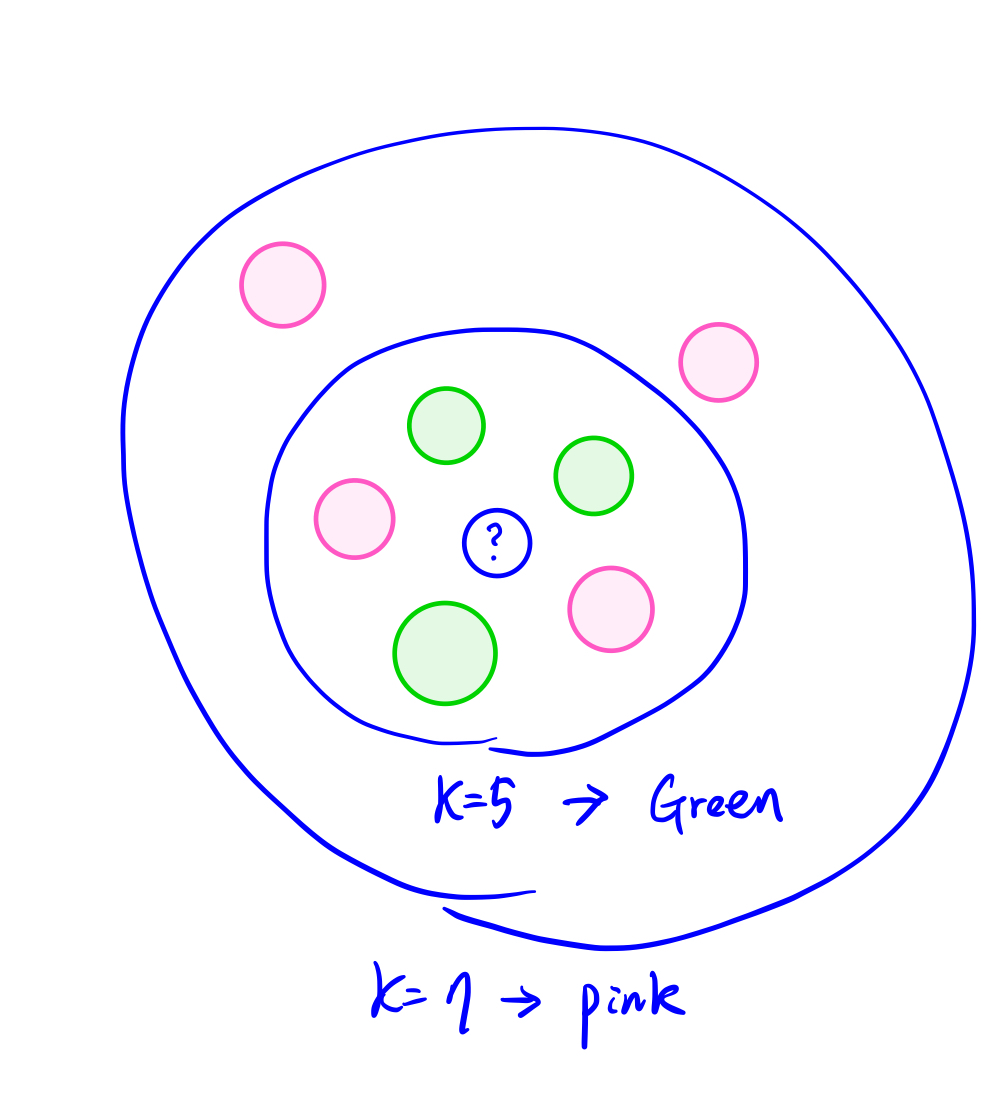
- K : 최근접 이웃의 개수, 하이퍼파라미터
- 최적의 K 값을 찾기 위해 파라미터를 튜닝(Cross Validation)
- 사기 탐지(Fraud Detection), 이상 감지(Anomaly Detection)에 적합
- 데이터 시각화를 통해 용이하게 분류 가능
- 다차원 공간에서 계산량이 급격히 증가함
- 예측자의 개수가 적고, 분류의 크기가 비슷할 때 사용 권장
Leave a comment